
티스토리 뷰
Apache Commons DBCP 2.9
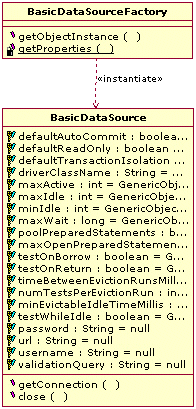
- 아파치의 커넥션 풀 오픈소스인 Commons DBCP는 BasicDataSource라는 타입으로 DataSource를 제공한다.
- 커넥션 풀 및 DataSource의 기본 개념이 필요하다면 포스팅을 참고해 주시길 바란다.
커넥션 풀 자료구조: LinkedBlockingDeque

DBCP2 기준으로 커넥션 풀은 LinkedBlockingDeque 타입의 객체로 관리된다. 아파치가 커넥션 풀 구현체는 덱 기반으로 한 이유는 'lifo' 설정 때문이다. 커넥션 풀 설정 값에 lifo라는 프로퍼티가 있는데, 이 값을 true로 할 경우 stack 기반으로, 그렇지 않을 경우엔 Queue 기반으로 동작한다. LinkedBlockingDeque의 요소는 Node 타입으로 정의되며 해당 Node들은 Doubly LinkedList 기반으로 동작한다. (prev, next 참조 변수 확인)
1. LinkedBlockingDeque의 쓰레드 간 동기화: ReentrantLock, Condition
LinkedBlockingDeque은 Java의 ReentrantLock을 기반으로 쓰레드 간 동기화 작업을 구현한다. LinkedBlockingDeque에 정의된 offer, peek, poll, contains, size 등 일반적인 Stack, Queue API와 동일한 메소드들이 정의되어 있으며 해당 모든 메소드들은 ReentrantLock을 기반으로 동기화 작업을 구현한다.
예시
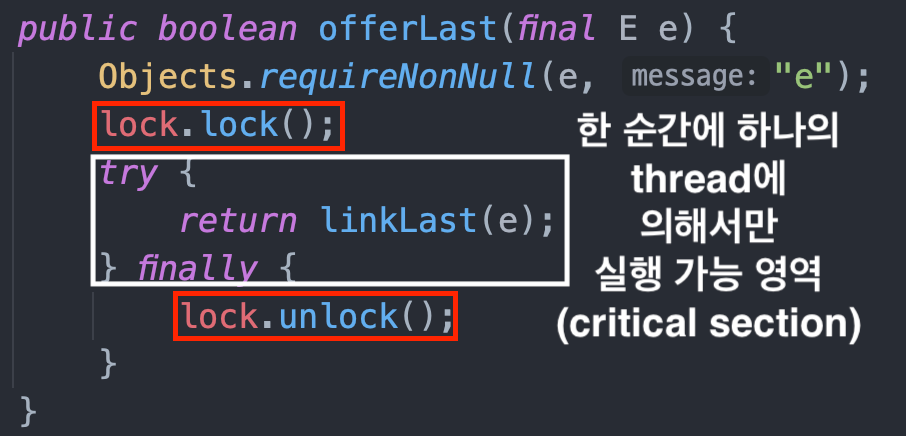
위 offerLast 메소드는 LinkedBlockingDeque에 정의된 메소드들이 쓰레드 간 동기화를 어떻게 해결해주는지 보여주는 예시이다. LinkedBlockingDeque의 대부분의 메소드가 위와 같이 메소드 시작 시 lock을 얻고 끝날 때 unlock하는 방식으로 구현되어 있다.
cf. ReentrantLock (from jdk5 Concurrent package)
ReentrantLock의 Java 표준으로 제공되는 lock API로써 아래와 같이 synchronized 키워드를 통한 동기화보다 더 향상된 기능들을 제공한다.
1) 코드가 단일 블록을 넘어서는 경우에도 사용 가능 (unlock 시점 중요)
2) synchronized block을 대기하는 쓰레드는 인터럽트 될 수 없으나 ReentrantLock은 인터럽트 가능
3) Waiting Pool에 있는 쓰레드에 ‘선별적으로’ 인터럽트 가능 (Condition class)
- synchronized에서 사용하는 Object.notify()는 waiting 쓰레드들 중 하나를 임의로 깨우는 방식
- ReentrantLock 생성자에 fair 옵션을 true로 주면 가장 오래 기다린 쓰레드를 먼저 unlock 수 있음
4) tryLock()을 통해 실제 lock을 잡을 수 있는 타이밍에만 lock실행 가능
- 이를 활용해 스핀락을 구현할 수 있으며 critical section의 수행시간이 짧을 때 유용
- Context switching 방지로 인한 성능 향상
ReentrantLock의 단점은 synchronized를 사용했을 때와 비교했을 때 나온다. synchronized를 사용하면 critical section에 대한 명확한 경계 설정이 가능하여 개발자의 실수를 방지할 수 있지만 ReentrantLock은 직접 lock 및 unlock을 호출해야 하기 때문에 만약 unlock이 제대로 되지 않을 경우 문제가 발생할 수 있다.
cf. Condition
- Java에서 제공되는 컴포넌트로 Lock과 함께 사용된다.
- “Critical section(lock~unlock구간)을 실행하는 동안” 특정 Condition이 발생할 때까지 쓰레드를 대기시키는 방식을 제공한다.
2. LinkedBlockingDeque 동작 방식
커넥션 풀 사용시 주로 동기화가 필요한 부분은 '풀로부터 커넥션을 빌려'오거나 '풀로 커넥션을 반납'하는 부분이다. 아래는 해당 두 부분에 대해 쓰레드 간 동기화 구현을 위해 ReentrantLock과 Condition이 어떻게 활용되는지를 분석한 결과이다.
1) '커넥션 반환 시' 쓰레드 동기화 동작 방식
일반적으로 커넥션 풀을 사용할 경우 Connection 객체의 close메소드가 호출될 때 풀로 반환되며 LinkedBlockingDeque의 경우 offerLast 또는 offerFirst가 호출된다. 그중에서도 lifo 설정을 true로 하여 offerFirst가 호출되도록 한 뒤, 디버깅을 한 결과 아래와 같다.
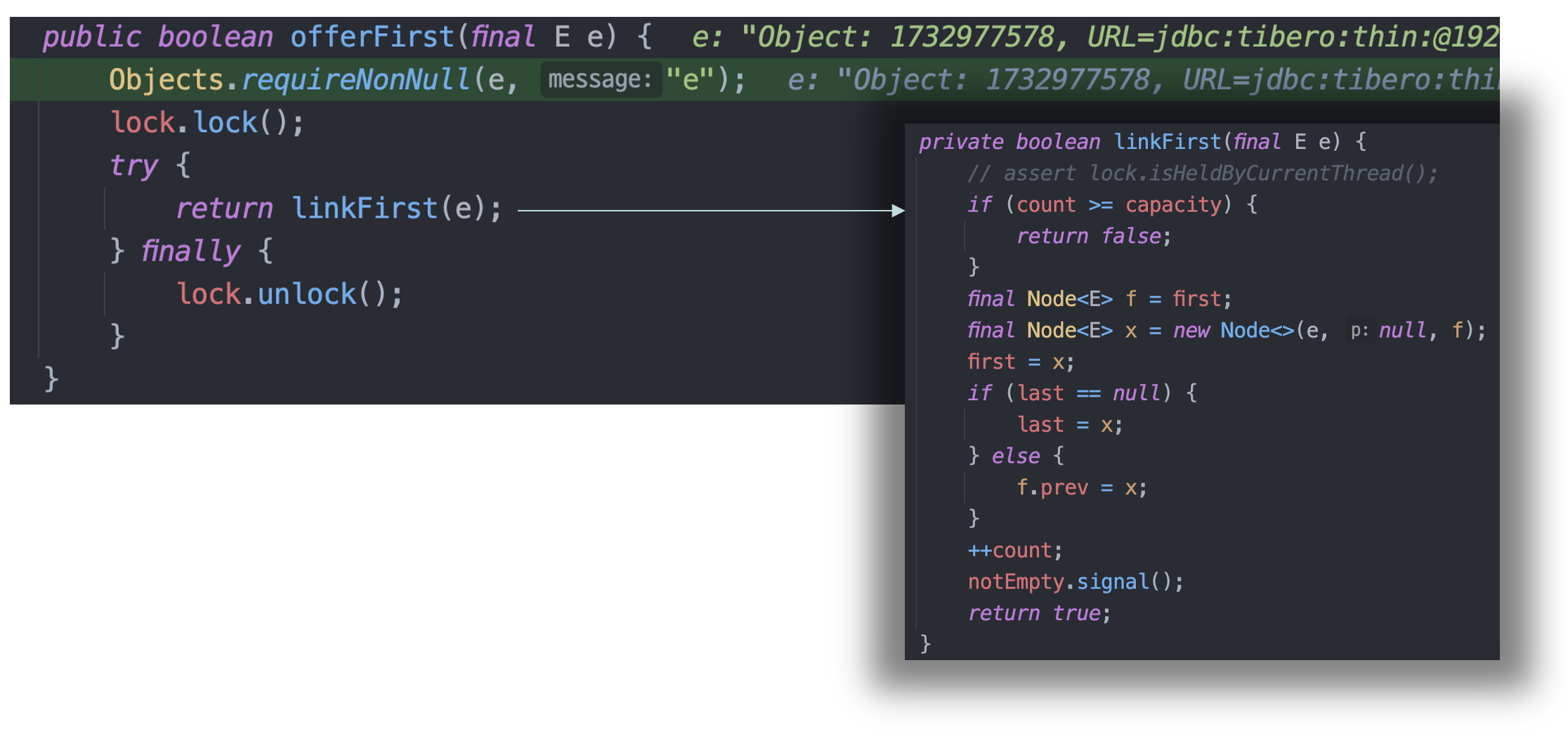
- offerFirst가 호출되면 lock 인스턴스(ReentrantLock 타입)에 대해 하나의 쓰레드가 lock을 획득한다.
- 그 뒤 커넥션 풀의 첫번째에 element를 link 하는 과정이 호출되는데, 해당 과정에서는 가장 첫 번째 위치에 element를 연결한 뒤 notEmpty라는 Condition 객체에 대해 singal을 호출한다. 즉, Pool에 커넥션이 추가되는 상황이므로 notEmpty라는 Condition에서 대기 중인 쓰레드를 깨운다.
- 마지막으로 lock 인스턴스에 대해 unlock을 호출하고 쓰레드는 빠져나온다.
2) getConnection (borrow) 시 쓰레드 동기화 동작 방식

커넥션 풀로부터 커넥션을 빌릴 때에는 'pollFirst/Last(maxWaitMillis)' 또는 'takeFirst/Last()' 메소드가 호출된다.
- pollFirst/Last(maxWaitMillis): pool에 idle 커넥션이 생기기를 maxWaitMillis만큼 대기
- takeFirst/Last(): pool에 idle 커넥션이 생기기를 ‘무한정’ 대기
또한 두 메소드에서는 풀에 커넥션이 없을 경우 기다려야 하는 상황이므로 notEmpty Condition에 대해 await를 호출하고 있음을 확인할 수 있다.
즉, 커넥션이 풀로 반납될 때 offerFirst가 호출된 뒤 linkFirst가 호출되면서 'notEmpty'라는 Condition을 기다리는 쓰레드(pollFirst 또는 takeFirst를 호출 중인 쓰레드)를 깨움으로써 해당 쓰레드가 반납된 커넥션을 풀로부터 가져갈 수 있게 되는 것이다.
Condition 객체의 동작 방식을 도식화하면 아래와 같다.

notEmpty라는 Condition에 대해 특정 쓰레드가 signal을 호출하면, notEmpty Condition을 기다리는 쓰레드 하나를 깨워서 해당 쓰레드가 동작할 수 있도록 한다.
Health Checking 및 Validation
Apache Commons DBCP2.9는 커넥션에 대한 health Checking 및 Validation 기능도 제공한다.
health Checking 및 Validation이 필요한 이유
1) health Checking 및 Validation은 유효한 커넥션 객체를 애플리케이션이 사용할 수 있도록 하기 위한 목적이 있다.
2) 기본적으로 DBMS는 시스템 자원 관리 측면에서 TCP 커넥션을 맺은 뒤 일정 시간동안 요청이 없으면 소켓을 닫아 해당 커넥션을 폐기한다. 얼마나 그 시간을 기다릴지에 대한 설정은 DBMS 별로 다르지만 보통 session timeout을 의미하는 값으로 사용된다. 즉, 해당 seesion timeout 값을 갱신하기 위한 용도로 Validation을 진행하기도 한다. 이때 Validation을 위한 경량의 쿼리를 사용하여 실제 DBMS로 요청을 보낸다.
cf. Session Timeout에 대한 오해
위에서 말한 Session Timeout은 DBMS가 자체적으로 관리하는 값이며 OS에서 관리하는 TCP Connection Timeout이나 Read Timeout과 같이 '개별 요청에 대한 timeout' 설정과 혼동해서는 안됨.
아래와 같이 아파치 커넥션 풀은 health Checking 및 Validation을 진행할 시점을 설정할 수 있도록 지원한다. (2.9 기준)
1) testOnCreate
- 커넥션 생성과 동시에 validation 진행 (기본값 false)
- 커넥션이 생성되었다는 것은 이미 DBMS에 로그인된 상태이지만 실제로 쿼리가 정상적으로 실행되느냐를 검사하는 설정
2) testOnBorrow
- getConnection시 validation(session timeout 갱신) 진행.
- 만약 해당 커넥션이 유효하지 않다면 폐기 후 새로운 커넥션 생성(기본값: true)
3) testOnReturn
- 커넥션을 반납하기 전에 validation 진행(기본값: false)
4) testWhileIdle
- 위 다른 시점과 다르게 Evictor 쓰레드(Runnable)라는 쓰레드를 추가적으로 사용하여 해당 쓰레드가 validation 진행
- Evictor 쓰레드는 timeBetweenEvictionRunsMillis 주기를 간격으로 구동되며 idle 커넥션을 검사하고 유효하지 않은 커넥션은 폐기함
testWhileIdle 설정을 활성화했다면 Evictor 쓰레드에 대한 결정도 함께 진행해야 한다. 아래는 Evictor 쓰레드 관련 설정이다.
- timeBetweenEvictionRunsMillis: evictor 쓰레드 구동 주기
- numTestsPerEvictionRun: evictor가 구동될 때마다 검사할 커넥션 개수
- minEvictableIdleTimeMillis: evictor에 의해 커넥션이 제거되기 전에 커넥션이 풀에 idle 상태로 보장될 수 있는 최소 시간
- softMinEvictableIdleTimeMillis: idle 상태더라도 연결된 지 X분 이하인 것들을 validation 대상에서 제외. 동시에 최소 minIdle 개수만큼은 풀에 유지
cf. numTestsPerEvictionRun와 timeBetweenEvictionRunsMillis의 관계도
만약 커넥션 풀에 최대 개수가 12개이고 DBMS에서 요청이 안오면 커넥션을 닫는 시간(session timeout)이 30분이라면 30분 내로 커넥션 풀에 있는 모든 커넥션에 대한 health check(유효 시간 '갱신')를 진행해야 한다. 여기서 timeBetweenEvictionRunsMillis를 10분이라고 했다면 numTestsPerEvictionRun는 4가 되어야 30분 내에 풀에 있는 모든 커넥션(maxIdle)을 검사할 수 있을 것이다.
Evictor 쓰레드

Eviction 과정
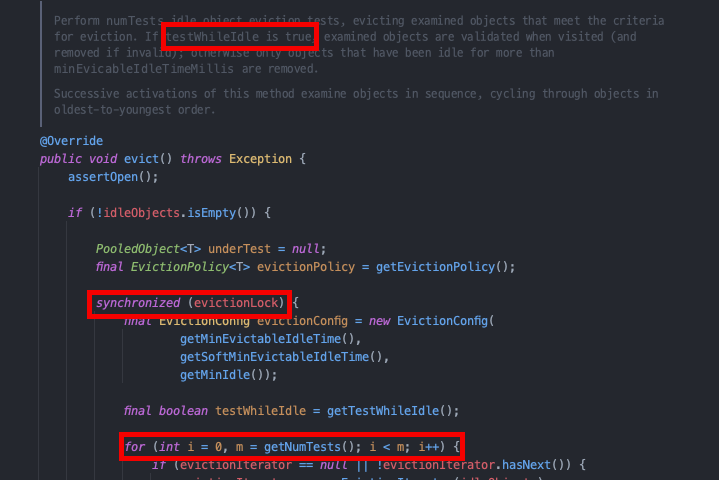
- evictionLock 객체에 대해 synchronized block을 설정하여 evict 과정 자체가 동시에 2개 이상 실행되지 않도록 동기화하고 있다.
- for문을 통해 커넥션 풀의 커넥션을 numTestsPerEvictionRun개만큼 꺼내서 evcition이 동작한다.
커넥션 풀 성능 개선을 위한 대표적인 설정들
1. 커넥션 풀 개수 관리
백엔드 애플리케이션의 성능에 영향을 미치는 중요한 요수 중 하나는 커넥션 풀 개수에 대한 설정이다. 풀을 너무 크게 하면 시스템 리소스를 많이 사용하게 되고 너무 적게 사용한다면 동시에 발생하는 요청들에 대한 응답 시간이 늦어질 수도 있다.
1) initialSize: 최초로 getConnection() 메서드를 호출할 때 커넥션 풀에 채워 넣을 커넥션 개수(기본값: 0)
2) maxTotal: 동시에 활성화될 수 있는 최대 커넥션 개수(기본값: 8, 음수일 경우 제한 없음)
3) maxIdle: 커넥션 풀에 반납될 때 풀이 최대로 유지할 수 있는 커넥션 개수(기본값: 8, 음수일 경우 제한 없음)
4) minIdle: 빌릴 때 풀에 최소한으로 유지할 커넥션 개수(기본값: 0)
여기서 궁금한 점은 'minIdle이 왜 존재하는가'이다. 얼핏 보면 최대 풀 개수만 보장되면 풀이 역할을 하는데 문제가 없을 것이라고 생각된다. 맞는 말이지만 minIdle은 풀의 역할보다는 풀의 성능과 관련된 설정이다. 위 설정 값들의 우선순위를 따져보면 minIdle보다 maxTotal이 크다. 예를 들어, minIdle 2, maxTotal 3, 현재 풀에 idle 커넥션이 2개 있는 상태에서 커넥션 borrow요청이 왔으면 커넥션을 빌려주고 minIdle을 만족하기 위해 즉시 1개를 더 생성한다. 즉, minIdle을 통해 최소한으로 풀에 커넥션을 유지시킴으로써 getConnection 요청이 왔을 때 커넥션을 생성하는 게 아니라 이미 생성된 커넥션을 바로 반환할 수 있게 된 것이다.
maxTotal = maxIdle = minIdle 일 경우 커넥션 풀 사이즈를 고정시키는 효과가 있다. 따라서 동시다발적으로 오는 요청에 대해 커넥션 생성에 대한 오버헤드를 감소시킬 수 있다.
cf. 주의사항
커넥션 풀의 개수는 DBMS가 감당할 수 있는 최대 sesseion 개수와 연관이 있다. DBMS에서 만약 최대 session 개수를 100으로 두었다면 커넥션 풀이 생성할 수 있는 최대 커넥션 개수(active, idle 모두 포함)도 100이 된다. 만약 백엔드 애플리케이션을 scale-out 할 상황까지 고려한다면 하나의 커넥션 풀 구현체가 최대로 사용할 수 있는 커넥션 개수는 'DBMS의 최대 session 개수 / replicas 수'가 될 것이다.
2. 커넥션 반환 대기시간
아파치의 커넥션 풀 구현체는 getConnection 요청을 했을 때 풀에 idle 커넥션이 없다면 해당 쓰레드를 block 시키는 방식으로 동작한다. 이때 해당 쓰레드를 얼마나 기다리게 할 지에 대한 설정이 'maxWaitMillis'이다. 트래픽이 급증한 시점을 생각해 보면, maxWaitMillis을 너무 크게 하면 사용자가 기다리다 스스로 웹 서비스를 꺼버릴 것이며 뿐만 아니라 사용 가능한 백엔드 애플리케이션의 쓰레드 수가 부족하게 되어 문제를 유발할 수도 있다. 반대로 maxWaitMillis가 너무 작으면 너무 잦은 에러 메시지가 응답될 것이다. 따라서 maxWaitMillis은 성능 개선을 위한 중요한 설정 중 하나이다.
3. 쿼리 타임아웃
defaultQueryTimeout 프로퍼티를 통해 개별 SQL(Statement)에 사용될 ‘논리적인’ timeout(기본값 무한대)을 제공한다. 기본값이 무한대이기 때문에 혹시나 DB서버에 장애가 발생하여 응답이 오지 못하는 상황이 발생한다면 애플리케이션 응답시간에 부정적인 영향을 줄 것이다.
4. Health Checking 설정
아파치의 커넥션 풀은 풀의 idle 한 커넥션에 대해 health checking을 할 때, 실제 경량의 쿼리를 DBMS로 요청하여 session timeout이 갱신되는 방식으로 구동된다. 만약 testWhileIdle 옵션을 활성화했다면 evictor 쓰레드의 구동 주기(timeBetweenEvictionRunsMillis)와 evictor가 한 번 구동될 때 검사할 커넥션 개수(numTestsPerEvictionRun) 설정을 유의해야 한다. 왜냐하면 실제 DB서버로 요청을 보내는 작업이기 때문에 너무 자주 발생할 경우 불필요한 네트워크 I/O 작업에 대한 오버헤드가 증가될 수 있기 때문이다.
이뿐만 아니라 Evictor 쓰레드는 동작 시에 LinkedBlockingDeque의 API를 사용하여 커넥션을 조회하기 때문에 lock이 발생하는 지점이 자주 발생한다. 따라서 너무 자주 실행하면 서비스 실행에 부담을 줄 수 있다.
cf. HikariCP와 Apache Commons DBCP의 health checking 방식 차이
1) HikariCP
- 커넥션 생성 시 커넥션이 유효한 maxLifeTime과 생성시간을 설정 (Session Timeout 보다 작게 설정 필요)
- getConnection 및 close시 현재 시간과 생성시간을 비교하여 maxLifeTime을 초과하는지 검사
- 커넥션의 maxLifeTime 값이 초과되면 해당 Connection을 폐기하고 새로 생성
- 실제 DB로 경량의 쿼리를 이용해 요청을 보낼 필요가 없음(트래픽 감소)
- 단, maxLifetime이 지난 커넥션을 폐기하고 새로 생성해야 한다는 오버헤드 존재
2) Apache Commons DBCP
- 실제 경량의 쿼리를 DB서버로 요청하여 'session timeout'을 갱신하는 방식
- 네트워크 I/O 작업이 동반되기 때문에 성능 영향을 줄 수 있음
- 성능에 문제가 되지 않을 만큼 설정을 한다면 커넥션 신규 생성을 방지하고 재사용을 최대한 활용할 수 있음.
[HikariCP의 validation에 대한 설명 추가]

실제 쿼리를 수행하는 방식이 아니기 때문에 DB와 의존 관계를 분리한 효과이다. 따라서 지속적으로 유효성을 체크하지 않아도 되며, 내부적으로 커넥션이 maxLifetime이 초과했는지만 계산하면 된다. 즉, 개발자가 지정한, maxLifetime 만큼 커넥션을 유지하고, 종료되면 새로 커넥션을 생성하는 사이클이 반복되는 방식이다. 커넥션을 재생성할 때에도, 커넥션 삭제 후 바로 생성하지 않고 약간의 시간 간격을 두어 '순차적으로' 커넥션을 생성한다고 한다. 따라서 최대한 부하를 줄이는 것이 HikariCP의 사상인 것 같다.
Statement Pooling
Statement Pooling은 JDBC 3.0에 정의된 명세이다. 커넥션을 풀링 하는 것과 마찬가지로 Statement에 대해서도 풀링을 지원하는 기능이다.
1. Statement Pooling을 사용하는 이유
Statement Pooling을 사용하는 이유를 이해하려면 JDBC상에서 Statement를 통해 쿼리를 수행했을 때 DBMS 상에서 처리되는 과정을 먼저 이해해야 한다.
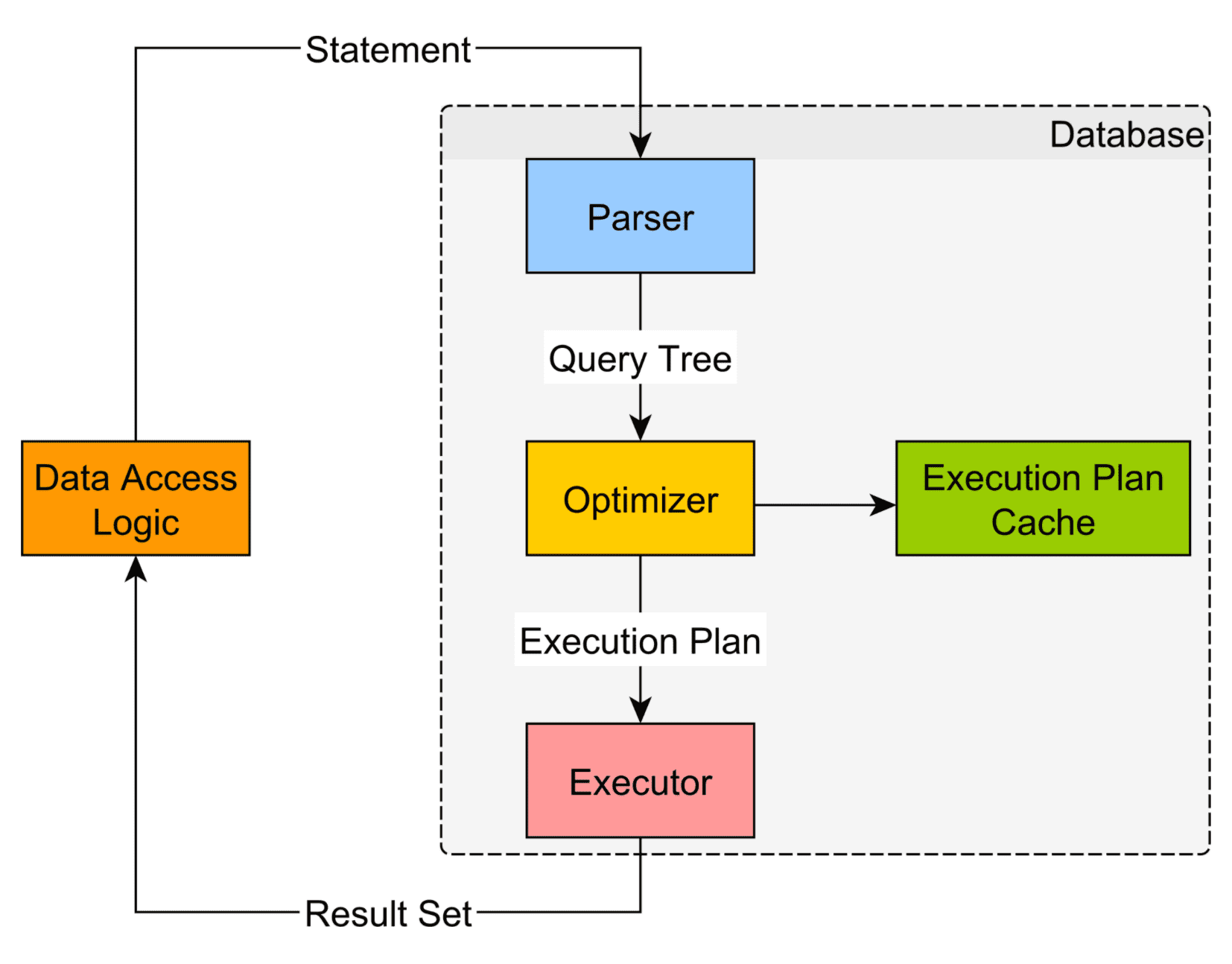
위 그림에서 볼 수 있듯이 DBMS에서 일반적으로 Statement를 처리하는 과정은 아래와 같다.
1) SQL parsing 및 문법 검사 후 트리 생성
2) 옵티마이저가 SQL실행을 위한 최적의 경로 결정(인덱스 결정, Join 순서 결정 등)
3) SQL 실행
위와 같이 JDBC에서 Statement를 생성하면 DBMS에서는 SQL에 대한 실행계획을 계산한다. 실행계획을 계산하는 것은 비용이 큰 작업이기 때문에 자주 사용되는 SQL(Statement)을 재사용하는 것이 Statement Pooling의 개념이다. 일반적으로 Statement를 close 하면 DBMS레벨에서도 해당 Statement의 실행계획을 파기하기 때문에 애플리케이션 레벨에서 해당 Statement 객체를 Pooling 하여 유지해야 한다.
2. 동작 방식
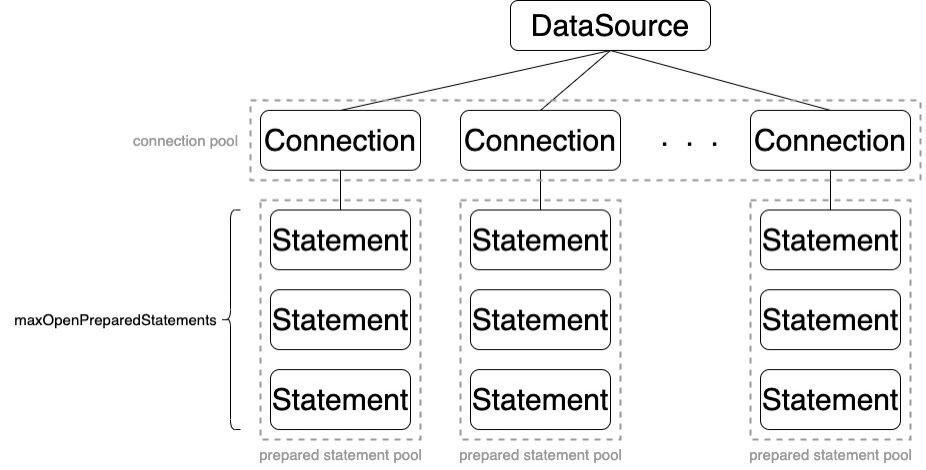
커넥션 풀과 마찬가지로 Statement Pooling 설정을 활성화한 뒤 Statement를 close 하면 Statement를 실제로 close 하지 않고 Statement Pool에 반환한다. Statement Pool에서 Statement를 찾을 때에는(Connection의 preparedStatement(sql) 호출 시) String으로 구성된 sql의 String Hash를 사용하여 Statement Pool에서 조회한다.
3. 사용 시 주의사항
1) Statement 생성과 초기화에 드는 비용을 줄일 수 있지만 메모리 사용량이 증가될 수 있으니 유의해야 한다. maxOpenPreparedStatements 값을 너무 크게 하면 클라이언트뿐만 아니라 DBMS단에서도 메모리 사용량이 증가된다.
2) Statement는 Connection에 종속되기 때문에 Connection을 풀에 반환하고 다시 사용할 때 이전에 사용했던 Connection이 아닌 다른 Connection이 할당될 수도 있으므로 이 경우에는 Statement Pooling이 비효율적으로 동작할 수도 있다. (출처)
3) 하나의 커넥션이 너무 다양한 쿼리를 수행할 경우에도 캐시 적중률(hit ratio)이 낮아지기 때문에 비효율적이다.
4. Statement vs PreparedStatement
SQL에 '?' 키워드를 통해 parameter를 추가할 수 있는 PreparedStatement에 대해 pooling을 제공함으로써 SQL이 이미 확정된 Statement보다 Caching을 더 효율적으로 사용할 수 있다. PreparedStatement의 특징을 살펴보면 parameter를 추가할 수 있는 부분이 대부분 value부분이다. 즉, 컬럼 이름이나 테이블 명에 대한 위치에는 parameter를 지정할 수 없다. 이러한 제약이 있는 이유에는 아마도 실행계획을 계산할 때 컬럼 이름이나 테이블 명은 이미 확정된 상태여야 하기 때문일 것이라고 생각한다. (실행계획 연산과 연관되는 부분에만 parameter 지원)
5. Commons DBCP의 Statement Pooling 설정
- poolPreparedStatements: true일 경우 Statement Pooling을 활성화한다. (기본값 false)
- maxOpenPreparedStatements: 커넥션당 풀링할 Statement 개수(정확히 말하면 PreparedStatement)
커넥션 풀 사용 시 주의사항
1. Connection에 대한 close 미호출
풀에 커넥션이 반환되지 않아 이후 요청(쓰레드)이 커넥션을 사용할 수 없게 된다. 이때 만약 maxWaitMillis 설정까지 기본값(무한대)을 사용한다면 쓰레드는 무한 block 된다. 보통 Spring과 같은 애플리케이션 프레임워크에서는 자동으로 close를 해준다.
2. rollback 및 commit 미호출
setAutoCommit(false)로 트랜잭션을 시작하며 commit 또는 rollback을 호출하지 않은 상태로 커넥션을 풀에 반환하면 치명적인 문제가 발생할 수 있다. 우선 트랜잭션을 끝내려면 commit / rollback을 호출해야 하는데, 그렇지 않은 경우 해당 트랜잭션이 DB상에서 잡고 있는 lock이 풀리지 않아 다른 트랜잭션에서 해당 DB row에 access 할 수 없게 된다. 참고로 MySQL이 사용하는 InnoDB 엔진에는 ‘innodb_rollback_on_timeout’ 설정을 지원하여 무제한 lock을 방지한다고 한다.
이뿐만 아니라 Connection이 실행 중이던 Statement를 가지고 있는 채로 풀로 반환된다는 점에서 논리적인 문제가 발생할 수도 있다. 예를 들어 만약 이러한 Connection이 풀로 반환되어 이후 다른 요청에서 해당 커넥션을 사용한다면 해당 요청은 실행하지도 않은 쿼리들이 갑자기 DB상에 반영됨으로써 발생할 수 있는 이슈가 있을 것이다.
3. 최대 풀 크기 설정
백엔드 애플리케이션이 scale-out 될 상황을 고려하여 최대 풀 크기를 설정해야 한다. 만약 DB서버에 replication이나 clustering이 구축되지 않은 상황에서(DB 서버가 한 대인 상황) 백엔드 애플리케이션을 scale-out 하면 해당 DBMS가 허용 가능한 세션의 개수를 초과하게 될 수도 있다.
추가적으로 알게 된 점
1. Connection 생성 원리
아파치 커넥션 풀 구현체를 분석하던 중에 커넥션이 생성되는 원리에 대해 궁금해서 직접 실습을 통해 알아봤다. 커넥션 풀 개념에 의하면 커넥션 풀에는 실제 ESTABLISHED 된 상태의 TCP 커넥션들이 저장되는 것으로 알고 있다. 따라서 getConnection 시 연결을 맺는 것이 아니라 이미 연결된 커넥션을 가져와 바로 사용하는 것으로 알고 있었다.
하지만 TCP 커넥션이란 "source의 IP, Port, destination의 IP, Port" 조합으로 구분된다는 사전지식이 있었기에 하나의 Java 프로세스에서 어떻게 여러 개의 커넥션을 맺을 수 있는 것인지에 대해 궁금했다. 즉, source IP, Port, destination의 IP, Port가 각각 아래와 같이 매칭되어 고정되어 있을 것이라 생각했다.
- source IP: 클라이언트 프로세스가 구동 중인 시스템의 IP
- source Port: JVM 프로세스 포트
- destination IP: DBMS가 구동 중인 시스템의 IP
- destinationPort: DBMS의 포트
그래서 커넥션 풀을 사용하여 커넥션이 6개 만들어지는 상황을 연출하고 (커넥션 사용 후 반납을 하지 않도록 구현한 서비스를 6번 호출) 생성된 TCP 커넥션을 확인해 봤다.

결과적으로 "단일 서버-클라이언트 프로세스 간에 2개 이상의 TCP 커넥션을 생성할 수 있었던 이유는 Source 포트를 다르게 함으로써 해결"했던 것이었다. 아마 JVM 프로세스가 할당받은 포트 범위 안에서 TCP 커넥션 개수만큼 생성할 수 있을 것이라고 추측된다.
2. 분산 트랜잭션 지원 여부(HikariCP)
HikariCP는 XA 기반의 커넥션 및 JTA를 지원하지 않는다. HikariCP의 빠른 성능의 사상과 맞지 않다는 것이다. 따라서 HikariCP를 통해 분산 트랜잭션을 처리하라면 XA가 아닌 다른 방식(보통 Eventual Consistency)을 사용하여 해결해야 할 것 같다. 이와 반대로 Apache Commons DBCP2.9는 XA 기반의 커넥션을 지원한다. 단일 DB에 대한 커넥션을 지원하는 BasicDataSource 클래스를 상속한 'BasicManagedDataSource'를 제공함으로써 XA를 지원하고 있다.
3. JDBC 리소스(Connection, Statement, ResultSet) 자동회수 지원
[Statement를 close 하지 않을 경우 발생할 수 있는 문제]
Statement는 SQL을 실행하기 위해 DBMS에서 ‘실행계획 연산 및 SQL 실행’을 위해 필요하다. Statement를 close 하지 않으면 DBMS 단에서도 해당 SQL 실행계획을 메모리상에 계속 상주해 두기 때문에 애플리케이션 및 DBMS 모두에서 메모리 낭비(Statement Pool을 사용하지 않을 경우를 가정)를 유발한다. Statement를 close 하지 않고 Connection만 close할 경우 Statement는 active상태로 남아 있지만 Connection이 close되었기 때문에 Statement를 close할 수 없는 상황이 발생할 수도 있다는 것이 문제가 된다.
[ResultSet을 close하지 않을 경우 발생할 수 있는 문제]
ResultSet은 SQL 결과를 만들기 위해 참조했던 데이터를 cursor라는 리소스로 남겨두는데 ResultSet을 close하지 않을 경우 사용 가능한 최대 cursor개수를 초과하여 더 이상 SQL을 실행할 수 없게 된다.
다행히도 JDBC 명세를 살펴본 결과 Statement를 close 할 때 해당 Statement가 생성한 ResultSet도 close 되도록 해야 한다는 내용을 찾아볼 수 있었다.
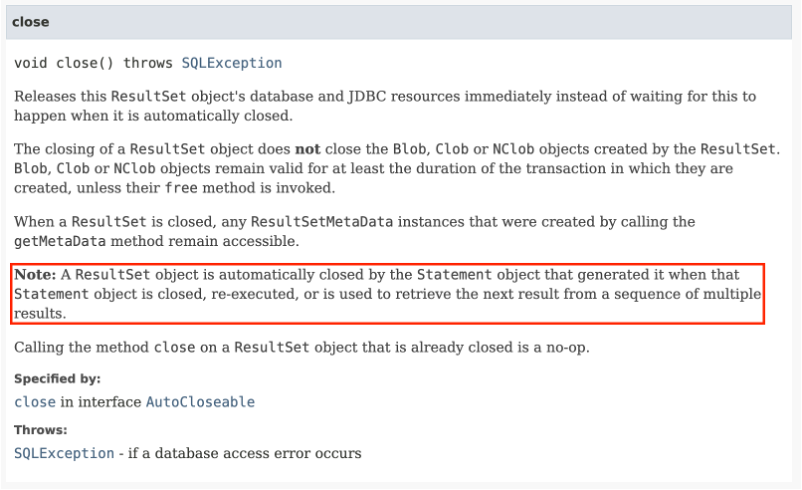
결국 Connection이 close 될 때 Statement도 close 되도록 구현된다면, Connection에 대해서만 close를 호출하면 해당 Connection과 관련된 Statement, ResultSet도 모두 close가 되는 것이다. 그래서 Apache Commons DBCP2.9의 커넥션의 close 메소드를 살펴본 결과 아래와 같다.
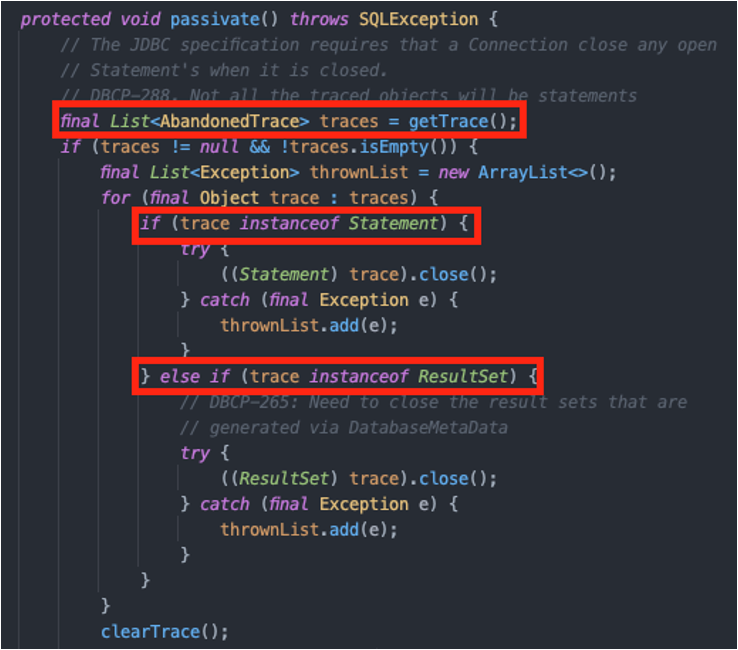
passivate()는 Connection의 close 메소드 실행 과정 중 초기에 호출되는 메소드이다. passivate() 내용을 살펴보면 현재 Connection이 실행한 Statement나 ResultSet을 traces 리스트로 가지고 있다가 Connection과 연관된 Statement, ResultSet을 모두 close 해주고 있음을 확인할 수 있다.
즉, Apache Commons DBCP2에서 제공하는 Connection을 사용하면 개발자가 직접 JDBC Resource에 close를 해 줄 필요가 없고 풀에서 빌려온 Connection 객체에 대해서만 close를 호출하면 된다. 만약 Statement Pooling을 사용할 경우 해당 Statement는 풀로 반환될 것이고 그렇지 않으면 DBMS로 close요청이 호출되어 DBMS 레벨에서도 메모리 상에 저장된 Statement(실행계획 관련 정보)가 삭제될 것이다.
4. NoSQL의 JDBC 지원 여부
MongoDB 같은 NoSQL은 각 DB마다 오퍼레이션이 다르다. JDBC는 관계형 데이터베이스의 일관된 SQL 문법으로 작성된 것을 표준화한 인터페이스이다. 따라서 JDBC로 MongoDB 같은 데이터베이스를 사용하는 것은 JDBC 사상과 맞지 않다. 단, JDBC를 통해 MongoDB로 질의를 요청할 순 있으나, 이는 MongoDB에 SQL문법으로 질의를 하는 것이다. 이런 UnityJDBC를 사용할 경우 join과 같이 SQL에 특화된 연산은 사용할 수 없다.
cf. 기본값을 그대로 사용하길 권장하는 옵션
1. removeAbandoned
removeAbandoned 옵션은 false가 기본값이다. removeAbandoned 옵션은 오랫동안 열려만 있고 Connection.close() 메서드가 호출되지 않는 커넥션을 임의로 닫는 기능을 제공한다. removeAbandoned 옵션을 true로 설정하고 removeAbandonedTimeout 옵션에 허용할 최대 시간을 지정하면 Commons DBCP에서 자동으로 Connection.close() 메서드를 호출한다. 만약 개발자가 Connection의 close를 호출하지 않아 풀에 회수되지 않았다고 가정하면 이후 요청들은 커넥션을 사용할 수 없기 때문에 요청이 block 된다. 하지만 이 문제를 해결하기 위해 removeAbandoned를 사용하는 것은 옳은 방법인 것 같지는 않다.
2. defaultAutoCommit
defaultAutoCommit 속성은 true가 기본값이다. 이 속성을 false로 설정하면 커넥션을 커넥션 풀에서 꺼낼 때 바로 setAutocommit(false) 메서드를 호출해서 트랜잭션을 시작하겠다는 의미다. defaultAutoCommit 속성을 false로 설정하면 애플리케이션에서 실수로 commit을 하지 않으면 INSERT 쿼리나 UPDATE 쿼리가 제대로 반영되지 않는다. select라고 해도 DB row에 대한 shared lock을 유지하기 때문에 성능 상 좋지 못한 결과가 도출될 수 있다. 따라서 기본값인 true를 그대로 사용하고 커넥션을 사용하는 애플리케이션 쪽에서 트랜잭션으로 묶고 싶은 부분을 직접 setAutoCommit(false)로 시작하고 commit 또는 rollback을 호출하여 종료하는 것이 무난하다.
Reference
- naver d2, https://d2.naver.com/helloworld/5102792
- Apache DBCP2.9 Configuration docs, https://commons.apache.org/proper/commons-dbcp/configuration.html
- HikariCP, https://github.com/brettwooldridge/HikariCP
- HikariCP vs Apache Commons DBCP, https://kakaocommerce.tistory.com/45
- JDBC timeout 이해, https://d2.naver.com/helloworld/1321
- Apache Commons DBCP2.9 WIKI, https://cwiki.apache.org/confluence/display/commons/DBCP
- Apache Commons DBCP2.9 API docs, https://commons.apache.org/proper/commons-dbcp/apidocs/index.html
- Java8 lock API docs, https://docs.oracle.com/javase/8/docs/api/java/util/concurrent/locks/Lock.html
- Baeldung Java lock, https://www.baeldung.com/java-concurrent-locks
- hitachi Statement Pooling, http://itdoc.hitachi.co.jp/manuals/3020/30203Y0410e/EY040199.HTM
'[ Basic ] > # 데이터베이스' 카테고리의 다른 글
| [DB] 알아두면 좋은 데이터베이스 설계 지식 (파티셔닝, 레플리케이션, 클러스터링) (0) | 2022.10.13 |
|---|---|
| [DB] Lock 기반으로 트랜잭션 격리수준 이해하기 (2) | 2022.06.20 |
| [DB] DB드라이버, 커넥션 풀, DataSource (0) | 2022.06.19 |
| [DB] Clustered / Non-Clustered Index (0) | 2022.05.31 |
| <추천글>[DB] Index 종류와 카디널리티 (0) | 2022.01.11 |
- Total
- Today
- Yesterday
- GitOps
- LFCS
- Kubernetes
- Controller
- Non-Blocking
- db
- Linux
- CICD
- 우분투
- jvm
- Java
- Stream
- 쿠버네티스
- golang
- 카프카
- K8s
- kafka
- argocd
- RDB
- 코틀린
- helm
- spring
- rolling update
- github actions
- container
- docker
- ci/cd
- ubuntu
- 컨트롤러
- go
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |