
티스토리 뷰
Type Of Index
- single level index
- composite index
- multilevel index
1. Single Level Index
- 인덱싱하는 컬럼이 1개인 경우에 해당함
- primary key에 걸면 Primary Index(기본 인덱스), 다른 컬럼에 걸면 Secondary Index(보조 인덱스)
- SQL문에서 where = {key1} = {value1} 가 하나인 경우 equality search가 빠르다.
- 메모리에 index table의 데이터 크기가 table보다 작음
- 카디널리티가 매우 낮은 컬럼이라면 인덱스를 지정하지 않는 것이 더 나을 수도 있음
[인덱스 정렬 타입]
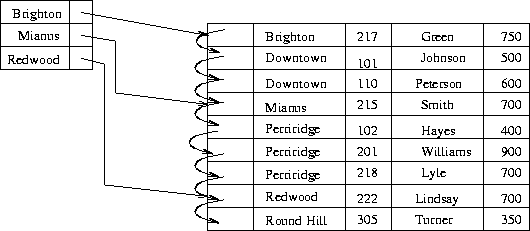
1) Dense Index(밀집 인덱스)
- 한 인덱스에 원하는 데이터가 바로 매칭됨
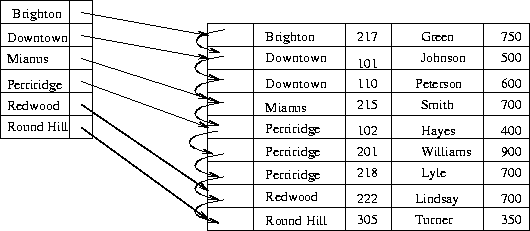
2) Sparse Index
- 인덱스를 블록단위로 관리함
- 블록 안에서 찾을 key값을 탐색하는 과정이 추가적으로 요구됨
- 메모리를 절약해 효율적인 인덱싱 가능
2. Composite Index **
- 여러 개의 컬럼에 인덱싱함
- 보통 SQL문에서 where = {key1} = {value1} and {key2} = {value2} and ... 처럼 여러 개의 조건으로 탐색할 시 적용함
- 인덱스를 설정할 컬럼의 순서가 중요한데, 인덱스를 (col1, col2) 순서로 지정했다면 첫 번째 컬럼인 col1을 먼저 찾고 그중에서 col2를 찾음
- 즉, 꼭 인덱스의 컬럼을 모두 사용해야만 인덱스가 사용되는 것은 아님.
- 따라서 빈도수가 적은 col을 인덱스에서 가장 앞단에 설정하는 것이 데이터를 많이 걸러낼 수 있기 때문에 효율적임(최대한 index full scan을 피함)
- 빈도수가 적다는 것은 중복이 적음을 의미하고, 이는 '카디널리티가 높은 컬럼'을 의미함
cf. 카디널리티 예시
- 성별에 대한 카디널리티 : 남/녀 두 가지일 경우 카디널리티는 2이다
- 날짜에 대한 카디널리티 : 월~일까지 존재할 수 있다면 카디널리티는 7이다
-> 여기서 만약 성별과 날짜 컬럼으로 composite index를 설정한다면 (성별, 날짜) 보다 (날짜, 성별) 형태로 인덱스를 생성하는 것이 유리함. 즉, 카디널리티가 높은 날짜 컬럼을 우선 탐색되도록 해서 최대한 index full sacn을 줄여야 한다.
cf. 인덱싱 선정 조건
- 만약 카디널리티가 낮다면, 인덱싱을 하는 것 자체가 메모리 효율상에서 비효율적이고, 성능상 이점도 가져갈 수 없다.
- 따라서 카디널리티를 고려해서 인덱스를 할지, 말 지 정해야 한다.
- 이외에도 선택도나 활용도 등을 고려 해야 함
3. Multi level Index

- 인덱스가 또 다른 인덱스를 위해 존재하는 형태임
- 테이블의 데이터가 다양해지고 커짐에 따라 single-level 인덱스의 데이터 양도 방대해짐
- single-level 인덱스의 경우 메모리 상에 상주하는데, 이로 인해 메모리 효율이 좋지 못함
- 따라서 인덱스를 계층화해 outer index만을 메모리에 두고 나머지 인덱스를 디스크에 저장하도록 함
- 단점은 I/O 작업이 많이 발생한다는 것임 (멀티 레벨 인덱스로 할 경우 인덱스가 메모리가 아닌 디스크에 저장되기 때문)
DML에서의 Index
- select절은 인덱스의 B Tree 구조를 변형시키지 않기 때문에 효율이 좋으나, delete, update, insert는 select보다 좋지 못함
- 즉, insert, update, delete의 성능을 희생하는 대신 select의 성능을 향상시킴
- select 쿼리는 B Tree 구조를 변형시지 않음
- delete, update, insert의 경우 B Tree구조를 변형시킬 수도 있고 그렇지 않을 수도 있음. delete, insert등의 쿼리 자체가 느린것이지 delete, insert의 where절에서 탐색하는 성능은 좋음
- 인덱스는 결국 데이터를 탐색할 때 사용되는 것이므로 DML에서 where절이 없다면 활용되지 않음
- B Trree는 항상 정렬된 상태로 유지하며 한 노드당 데이터가 여러개 들어간다는 점을 생각해야 함
인덱스가 너무 많아도 좋지 않다
- 데이터가 삽입, 삭제될 때마다 관련된 인덱스들도 모두 수정해줘야 함
- 인덱스는 기본적을 메모리에 저장되기 때문에(디스크에 저장될 수도 있음) 적절하게 사용해야 함
- 옵티마이저가 들어온 쿼리에 대해 적용할 인덱스를 선택하는데 인덱스가 너무 많으면 옵티마이저가 최적의 인덱스를 선택하지 않을 수도 있음(힌트사용으로 해결가능)
- 테이블 당 2~3개가 적당
cf. 인덱스를 구성하는 B Tree 자료구조 -> https://jh-labs.tistory.com/147
인덱스 사용시 주의사항
- in, = 연산자는 인덱스를 사용한다. (in은 =를 여러번 수행한 결과이기 때문)
- 하지만 in 연산자 뒤에 서브쿼리를 넣으면 서브쿼리로 인한 성능상 이슈가 발생함
- between, like, <, > 연산자는 인덱스가 적용되지만 그 이후의 컬럼은 인덱스가 적용되지 않음. 예를들어 인덱스가 (A, B, C)로 설정되어 있고, where B < 10 and C = 3 and A = 1 과 같은 쿼리가 온다면 A, B까지는 인덱스가 적용되지만, 이 이후인 C에 대해서는 인덱스가 적용되지 않음
- AND 연산자를 사용하면 각 조건을 검사하기 위해 읽어드릴 row 수가 적어지지만 OR 연산자를 사용하면 테이블 풀 스캔을 할 가능서이 높음
- where절에서 인덱스로 설정한 컬럼 값을 그대로 사용해야 인덱스가 적용된다. 예를들어, where member_id * 10 < 100 은 인덱스를 사용하지 않지만 where member_id < 10 은 인덱스를 사용한다.
- 타입이 다르면 인덱스가 적용되지 않는다. 예를들어, member_id의 컬럼이 bigint라 가정하면, where member_id = '1' 은 인덱스를 사용하지 않지만 where member_id = 1 은 인덱스를 사용한다.
Reference
- https://www2.cs.sfu.ca/CourseCentral/354/zaiane/material/notes/Chapter11/node5.html
- https://itholic.github.io/database-cardinality/
- https://www.tutorialspoint.com/dbms/dbms_indexing.htm
'[ Basic ] > # 데이터베이스' 카테고리의 다른 글
| [DB] DB드라이버, 커넥션 풀, DataSource (0) | 2022.06.19 |
|---|---|
| [DB] Clustered / Non-Clustered Index (0) | 2022.05.31 |
| <추천글>[DB] DB Index 자료구조 B-Tree 기본개념 (0) | 2022.01.03 |
| [DB] Index 적용 및 성능분석, 실행계획 분석 (0) | 2021.12.16 |
| <추천글>[DB] Transaction의 Isolation level을 나눠 둔 이유 (0) | 2021.11.29 |
- Total
- Today
- Yesterday
- argocd
- docker
- jvm
- 컨트롤러
- ci/cd
- CICD
- rolling update
- ubuntu
- 우분투
- spring
- RDB
- Non-Blocking
- 카프카
- container
- 코틀린
- kafka
- Linux
- Java
- db
- github actions
- golang
- Stream
- 쿠버네티스
- Controller
- Kubernetes
- GitOps
- LFCS
- go
- K8s
- helm
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |