
티스토리 뷰
ForkJoinPool은 기본 개념은 큰 업무를 작은 업무 단위로 쪼개고, 그것을 각기 다른 CPU에서 병렬로 실행한 후 결과를 취합하는 방식으로 분할정복 알고리즘과 유사하다. 대표적으로 Java에서는 병렬스트림을 사용할 때 사용된다.
ForkJoinPool 동작 방식
1) 큰 task를 작은 단위로 쪼갠다.
2) 부모 쓰레드로 부터 로직을 복사해서 새로운 쓰레드에 쪼개진 업무를 수행한다. - Fork 과정
3) 2번 과정을 수행하다가 특정 쓰레드에서 더 이상 Fork가 발생하지 않고(IDLE CPU의 개수와 작업량에 따라 어디까지 분할할지 내부적으로 결정됨) task 처리가 완료되었다면 그 결과를 부모 쓰레드에서 Join 하여 값을 '취합'한다. - Join 과정
4) 3번 과정을 반복하다가 최초의 ForkJoinPool을 생성한 쓰레드로 값이 취합되면 작업이 완료된다.
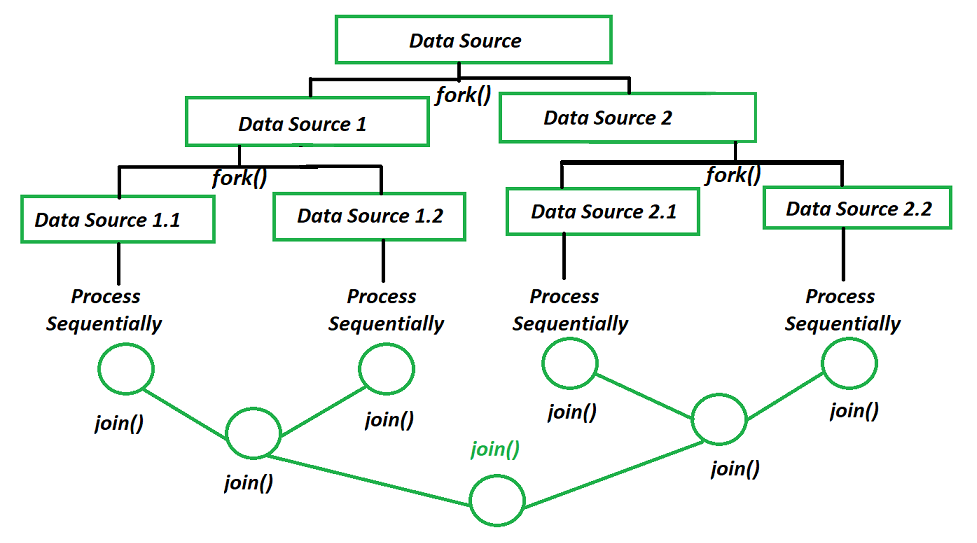
일반적인 쓰레드 풀과 ForkJoinPool의 차이점
- 만약 쪼개지는 작업이 모두 '동일한 작업'을 처리하게 된다면 ForkJoinPool은 좋은 선택이 아닐 수도 있다.
- 이와 다르게 작업이 서로 각각 달라서 특정 쓰레드에서는 오래 걸리는 작업이라면 ForkJoinPool은 좋은 선택지가 될 것이다.
- 기본적으로 멀티코어를 사용하는 프로그램의 속도는 프로그램 내부에 존재하는 순차적(sequential) 부분이 사용하는 시간에 의해서 제한된다.
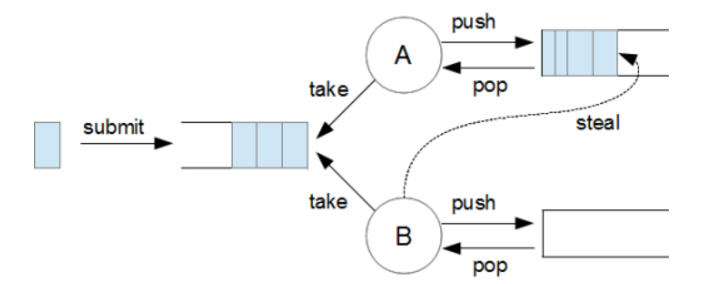
ThreadPoolExecutor와 마찬가지로 ForkJoinPool도 내부에 inbound queue라는 것을 자체적으로 두고 있다. 위 그림에서와 같이 task를 inbound queue에 submit 하면 하나의 inbound queue에 적재가 되고 A, B 쓰레드들이 inbound queue로부터 작업을 가져가 처리한다. 또한 A, B쓰레드는 각자가 queue(사실상 덱)를 가지며 inbound queue로부터 작업을 가져와 각자의 queue에 적재한다. 만약 각자의 queue에 작업이 없다면 다른 쓰레드의 queue에서 작업을 가져가 처리하기도 한다. 이러한 방식은 idle 코어를 줄일 수 있다는 장점이 있다.
위에서 언급한, 쓰레드 각자가 가지는 queue는 사실상 Dequeue으로 동작하며 ForkJoinPool의 핵심적인 부분이다. 여기서 Dequeue을 사용하는 이유는 "각 쓰레드는 stack처럼 앞에서만 일을 가져다가 처리하고 Dequeue의 끝부분에는 다른 쓰레드가 작업을 가져와서 자신의 Dequeue에 작업을 집어넣기 위함이다." (작업 큐가 비었을 경우에만 상대 쓰레드의 큐에서 작업을 가져온다.)
따라서 '동일한' 작업의 특성을 가지는 task가 아니라 '서로 다른' task를 가진 작업을 쪼갤때, idle 쓰레드가 다른 쓰레드의 작업을 가져가 처리할 수 있다는 점에서 ForkJoinPool을 활용해야 한다.
[추후 생각해볼 것들]
cf. 상대 쓰레드의 Dequeue으로부터 작업을 가져가려는 쓰레드가 여러개 있을 경우(경함 발생)에는 어떻게 처리하는가?
cf. inbound queue에서 작업을 가져갈 때 경합이 발생하면 어떻게 처리하는가?
cf. 기본적으로 ForkJoinPool과 같이 여러 쓰레드를 만들고 작업을 병렬적으로 처리하더라도 각각의 쓰레드가 작업을 처리하는 과정에서 만나는 blocking I/O가 발생하는 곳에서는 성능 저하가 발생할 수밖에 없다. 즉, 멀티 쓰레드로 동시에 작업을 수행하더라도 synchronized 블록이나 데이터베이스, 네트워크 API 호출 등을 만날 때 다른 쓰레드와 나란히 줄을 서서 순차적으로 작업을 수행해야 한다.
결국 병렬성을 최대한 잘 설계해도 이러한 순차적인(sequential) 작업이 처리되는 시간에 성능이 bound될 수밖에 없다. 따라서 작업을 여러 쓰레드로 분산시켜 처리하는 것이 무조건 좋다고 할 순 없다는 것이다. (비동기처리, 동기처리와 상관없이 작업의 특성 자체가 순차적이라는 것이 성능에 고질적으로 영향을 준다는 것)
Reference
- https://www.geeksforgeeks.org/difference-between-fork-join-framework-and-executorservice-in-java/
'[ Basic ] > # OS' 카테고리의 다른 글
| [ubuntu] apt의 이해 (0) | 2022.06.30 |
|---|---|
| <추천>[OS] Context Switching, Cache Pollution / TLB, MMU (0) | 2022.05.28 |
| [OS] 데몬(daemon) 프로세스, nohup, & (0) | 2022.01.03 |
| [OS] 현대 OS의 Deadlock 처리 (0) | 2021.11.22 |
| [OS] interrupt와 system call (0) | 2021.09.22 |
- Total
- Today
- Yesterday
- Kubernetes
- 우분투
- Stream
- jvm
- Non-Blocking
- rolling update
- Java
- spring
- go
- 쿠버네티스
- docker
- kafka
- Controller
- RDB
- argocd
- LFCS
- ci/cd
- ubuntu
- container
- github actions
- 컨트롤러
- Linux
- golang
- CICD
- 코틀린
- helm
- 카프카
- GitOps
- K8s
- db
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |