
티스토리 뷰
PCB(Process Control Block)
운영체제가 프로세스들을 관리하기 위해 사용하는 자료구조이다. 운영체제는 PCB 자료구조를 통해 프로세스 제어 및 관리(스케줄링, 종료, fork 등)를 한다. 아래 사진은 PCB가 갖는 데이터 구조이다.
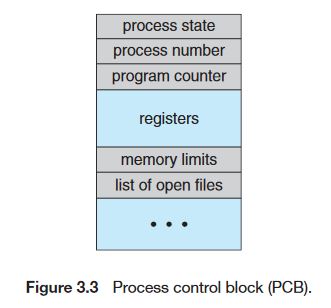
- process state : 프로세스의 상태(new ready waiting, running, terminated)
- process number : PID
- program counter : PC 레지스터 값(다음에 실행시킬 Instruction의 주소)
- registers : 프로세스가 스케줄링되어 있던 CPU의 레지스터의 값(Context Switching시 사용됨)
- memory-limits : 프로세스에 할당된 메모리 제한 정보(페이지 테이블 정보 또는 세그먼트 테이블의 base, limit 정보)
- list of open files : 프로세스가 수행한 I/O FD 정보(모든 I/O는 파일이라는 점을 생각해야 함)
리눅스에서의 쓰레드
사실 리눅스에서는 프로세스와 쓰레드를 구분하지 않고 Task로 총칭하기 때문에 PCB보다 TCB(Task Controller Block)이 더 맞는 용어인 것 같다. 실제로 리눅스에서는 task_struct라는 구조체를 통해 PCB(TCB)를 구현한다.
그렇다면 task 들을 보고 프로세스인지 쓰레드인지 어떻게 구분할까? - 'Address Space를 공유하는가'
결국 프로세스와 쓰레드는 Address Space를 공유하느냐/그렇지 않느냐에 따라 구분될 수 있다. 만약 두 task가 같은 Address Space를 공유한다면 이 두 task는 하나의 프로세스에 속한 두 쓰레드임을 짐작해 볼 수 있다. 반대로 임의의 두 task가 Address Space를 공유하지 않는다면 두 task는 서로 다른 프로세스에 속한 쓰레드이다.
프로세스와 쓰레드는 어떻게 만들어지는가? - 'fork, clone 시스템 콜'
리눅스에서 프로세스와 쓰레드를 만들기 위해선 fork, clone 시스템 콜이 사용된다.
1) fork
현재 프로세스와 '완전히 동일한 새로운' 프로세스를 생성한다. 이때 부모 task의 Address Space 등 컴퓨팅 리소스를 전혀 공유하지 않는, 완전히 새로운 프로세스를 생성한다. 따라서 부모 task의 Address Space 등을 모두 그대로 copy 해야 하는 오버헤드가 존재한다. 일반적으로 우리가 GUI 화면에서 프로그램 아이콘을 더블클릭을 통해 새로운 프로세스를 실행시키는 경우, fork -> exec 시스템 콜이 순서대로 호출되는 과정을 거친다.
2) clone
부모 task가 사용 중인 일부 자원을 공유하는 task(thread)를 생성한다. 그 자원을 얼마나 공유할지를 아래 옵션으로 설정할 수 있다.

- clone_vm : 부모 task와 address space를 공유한다. 이 옵션을 true로 준다면 쓰레드 생성이다.
- clone_fs : 부모 task와 파일 시스템을 공유한다.
- clone_files : 부모 task와 열려있는 파일을 공유한다. (I/O)
- clone_sighand : 부모 task와 signal handler를 공유한다.
- clone_pid : 부모 task의 PID를 공유한다.
만약 위 설정들을 모두 false로 준다면 fork와 같은 역할을 할 것이다.
task_struct와 context
사실 위에서 언급한 task는 task_struct라는 구조체로 관리된다. 프로세스의 정보는 쓰레드 간 공유하는 static한 정보일 것이다.(바뀔일이 거의 없음) 이러한 정보 외, 다른 dynamic한 정보(execution state)를 context라고 한다.
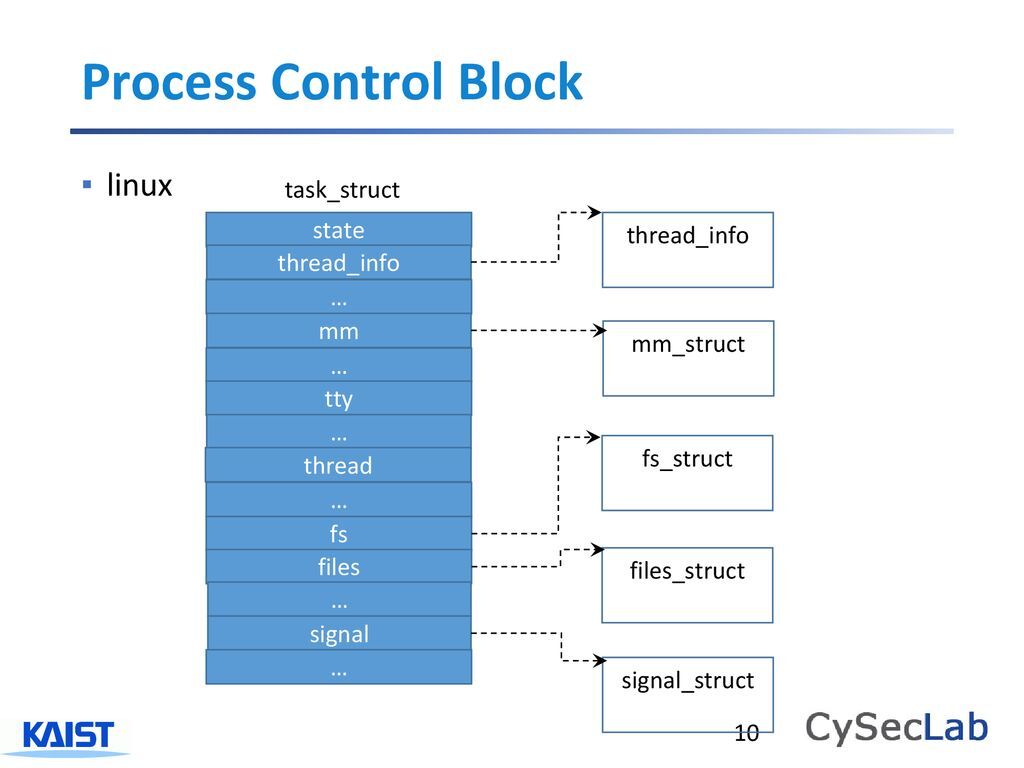
위와 같이 task_struct 구조체의 형태를 보면 다양한 다른 구조체의 포인터 변수를 가지고 있다. 그리고 mm_struct, fs_struct, files_struct, signal_struct 등과 같은 구조체는 보다 static한 성질의 프로세스의 정보를 담는다. 이러한 정보는 쓰레드 간 공유될 것이며 task_struct는 보다 dynamic한 task의 context 정보를 담는다.
프로세스 생성과 쓰레드 생성에 대한 고찰
결국 프로세스와 쓰레드는 모두 task_struct로 abstract되어 관리되기 때문에 프로세스 생성과 쓰레드 생성에 대한 오버헤드는 비슷하겠지만(프로세스 생성이든 쓰레드 생성이든 task_struct를 생성한다는 것은 같음), 부모 task와 자원을 전혀 공유하지 않는 프로세스 생성(fork)의 경우에는 memory copy에 대한 오버헤드가 존재하기 때문에 쓰레드 생성에 대한 오버헤드보다 클 것이라 생각 든다.
Context Switching
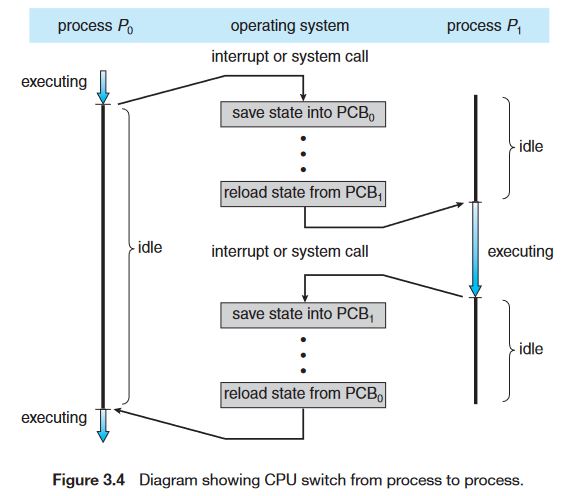
위 그림은 Single Core에서의 Context Switching의 과정을 나타낸다. 결국 Context Switching을 위해서 PCB를 메모리로부터 읽고 쓰는 인스트럭션(CPU cycle이 매우 큼)이 발생하기 때문에 CPU의 IDLE 시간이 발생하고 이러한 과정이 자주 발생할수록 오버헤드는 커질 것이다.
이뿐만이 아니다 스케줄러에 의해 다음에 실행시킬 task가 결정되면 해당 task의 정보를 메모리 상의 PCB로부터 읽어와 CPU의 레지스터에 적재시킨다 (context switch 발생). 그 뒤, OS는 다시 timer를 설정하고 CPU는 Kernel mode에서 User mode로 전환된다. 즉, mode switch로 인한 오버헤드 역시 존재한다.
Context Switching이 발생하는 시점
1) I/O 시스템 콜(read/write)이 발생했을 때
- I/O 작업 동안에 유저 쓰레드가 스케줄링된다면 CPU의 IDLE 타임이 커질 것이다. 따라서 I/O 시스템 콜이 발생한 시점에서는 waiting queue에 해당 task의 PCB가 들어가서 대기하며 I/O 완료에 대한 signal이 올 때까지 대기한다.
2) Timer에 의해 스케줄러가 실행될 경우
- 스케줄러는 task를 CPU에 할당할 때 Timer라는 하드웨어에 시간(timse slice, quantum)을 설정한다. Timer에서 시간 만료에 대한 Interrupt가 발생하면 CPU는 user mode에서 kernel mode로 바뀌고 스케줄러가 불린다.
3) System call / Exception / interrupt
- I/O 시스템 콜 외에도 다양한 시스템 콜에 의해 context switch가 발생할 수 있다. 또한 예외가 발생해서 task가 종료되어야 할 경우나 각종 하드웨어에 의한 interrupt(사용자가 프로세스 종료 키를 누름 등), 또는 사용 중인 자원에 대해 preemptive 되었을 경우(스케줄링 알고리즘에 따라 다름)에 의해서도 context switch가 발생할 수 있다.
Context Switching이 왜 필요한가 - 'Concurrency'
여러 개의 task들을 제한된 Processor에서 Concurrent 하게 실행시키기 위함이다. 즉, Processor가 무한대라면 스케줄링할 필요도 없을 것이다. 컴퓨터 리소스는 한정되어 있기 때문에 OS의 스케줄링 역량은 사용자 관점에서 매우 중요하며 이로써 OS는 하나의 Core에서 여러 task들을 Context Switching 함으로써 사용자에게 여러 task들이 동시에 실행되는 것처럼 보이게 할 수 있다.
Context Switching의 Cost
프로세스 간 context switching과 쓰레드 간 context switching에 대한 고찰
process switching / thread switching 모두 커널 모드에서 실행된다는 점과 CPU의 레지스터 값을 변경해줘야 한다는 점은 공통점이지만, process switching의 경우 "두 프로세스 간 Address Space(메모리 주소 체계)가 다르다는 점에서 차이점이 존재"한다.
OS가 context switching을 수행할 때 스케줄러에 의해 다음에 실행시킬 task가 결정된다면 해당 task가 이전에 실행 중이던 task와 같은 프로세스에 속하는지 검사한다. 즉, task_struct의 mm_struct 주소 값을 비교해 같은 Address Space를 갖는지 검사한다.
MMU(Memory Management Unit)
- MMU는 CPU에 존재하는 하드웨어로서 가상 주소를 물리 주소로 변환해주는 역할을 담당한다. CPU 또는 task는 가상 주소만을 바라보기 때문에 MMU의 역할이 필요한데, MMU가 주소를 변환하는 과정에서는 물리 주소의 base 주소 등 주소 변환을 위한 정보가 필요하다. 따라서 프로세스 간 Context Switching에서는 MMU에 대한 설정을 바꿔줄 필요가 있다.
TLB(Translation Lookaside Buffer)
가상 메모리를 갖는 시스템에서 갖는 단점은 Page Table을 level 만큼 접근해야 한다는 점이다. 예를 들어 3-level page table을 갖는 시스템에서 메모리 접근 1번을 하기 위해 3번의 page table을 접근해야 한다.(메모리를 3번 접근해야 한다는 것과 같은 말임)
이러한 문제를 해결하고자 TLB가 등장했다. TLB는 MMU가 가상 주소를 물리 주소로 변환한 결과를 임시적으로 저장하는 캐시라고 생각하면 된다. MMU가 주소 변환을 수행하면 그 결과를 OS에게 interrupt를 통해 알리고 해당 값을 OS가 TLB에 저장해둔다.
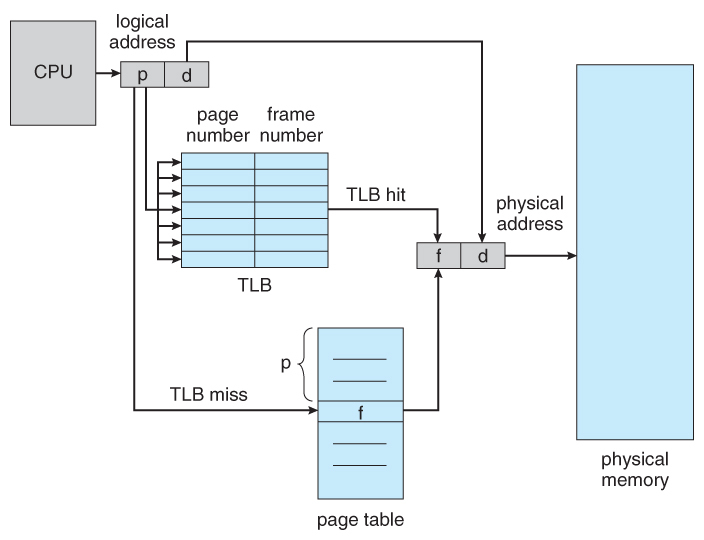
위 사진은 CPU에서 메모리 접근이 발생할 때 TLB hit / miss가 발생하는 과정을 보여준다. 그림과 같이 물리 주소를 찾는 과정에서 무작정 Page Table에서 찾는 것이 아니라(메모리 접근이 많이 발생) 최근에 translate된 주소가 TLB에 존재하는지 탐색한다. TLB hit이라면 바로 물리주소를 찾을 수 있지만 TLB miss가 발생하면 MMU는 Page Table에서 물리주소를 찾고 Interrupt를 발생시켜 OS가 해당 결과를 TLB에 저장한다.
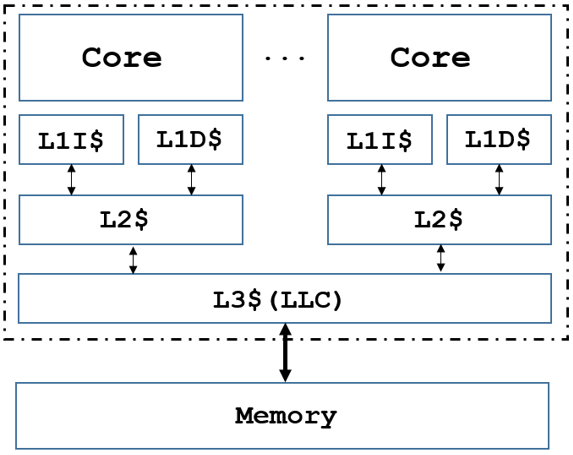
아무튼 서로 다른 프로세스는 서로 다른 메모리 주소체계를 바라보기 때문에, 프로세스 간 Context Switching이 발생할 경우에는 TLB 캐시를 모두 비워(flush) 줘야 한다. 이후 새로운 프로세스가 TLB를 채워가는 과정 자체가 TLB Miss이고 이 과정은 Page Table을 접근해야 한다는 이슈가 발생한다. (메모리 접근으로 인한 오버헤드 증가)
반면 (같은 프로세스에 속한)쓰레드 간 Context Switching일 경우, 이전의 task와 새로운 task가 모두 같은 Address Space(메모리 주소 체계)를 바라보기 때문에 TLB를 flush 할 필요가 없다.
따라서 process switching latency가 thread switching latency보다 크다고 볼 수 있다.
cf. TLB는 프로세서에 존재하는 데이터 버퍼이기 때문에 메모리에 접근하는 것보다 빠르다.
cf. TLB의 Address-Space Identifiers (ASIDs)
최근 등장한 TLB에서는 PID정보까지 저장하는 경향이 있다. 이를 통해 Context Switching이 발생하더라도 TLB에 PID를 가지고 있으므로 TLB를 flush할 필요가 없어졌다.
Context Switching의 고질적인 문제점 - 'Cache Pollution(캐시 오염)'
Context Switching이 발생하면 캐시의 데이터 값들은 의미가 없어질 것이다. 그나마 같은 프로세스에 속한 쓰레드 간 Context Switching일 경우에는 유의미한 캐시 데이터가 있을 가능성이 조금 더 있을 순 있다. 이렇듯 Context Switching으로 인해 캐시 데이터가 무의미해지며 Context Switching이후 Cache Miss가 빈번하게 발생하게 되는 문제를 'Cache Pollution(캐시 오염)'이라 한다.
이러한 문제점으로 인해 일부 아키텍처에서는 프로세스 간 Context Switching시에 캐시 데이터를 모두 flush 하는 시스템도 있다. 아무튼 캐시를 비우든/비우지 않든 Context Switching 직후에는 Cache Miss가 어쩔 수 없이 빈번하게 발생할 것이고 이로 인해 메모리 접근 횟수 또한 많아질 것이다. 따라서 Context Switching 자체는 어쩔 수 없는 오버헤드를 갖는다.
Reference
- clone system call : https://www.linuxjournal.com/article/3184
- https://www.cs.swarthmore.edu/~kwebb/cs45/s18/03-Process_Context_Switching_and_Scheduling.pdf
- https://en.wikipedia.org/wiki/Context_switch
- Operating System Concepts 9th
'[ Basic ] > # OS' 카테고리의 다른 글
| [ubuntu] apt의 이해 (0) | 2022.06.30 |
|---|---|
| [OS] ForkJoinPool (0) | 2022.06.18 |
| [OS] 데몬(daemon) 프로세스, nohup, & (0) | 2022.01.03 |
| [OS] 현대 OS의 Deadlock 처리 (0) | 2021.11.22 |
| [OS] interrupt와 system call (0) | 2021.09.22 |
- Total
- Today
- Yesterday
- ubuntu
- 쿠버네티스
- ci/cd
- 우분투
- Controller
- Non-Blocking
- helm
- jvm
- spring
- github actions
- Java
- 컨트롤러
- kafka
- 카프카
- argocd
- 코틀린
- GitOps
- docker
- Kubernetes
- go
- LFCS
- rolling update
- CICD
- golang
- RDB
- Stream
- db
- container
- K8s
- Linux
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |