
티스토리 뷰
쓰레드 생성 과정
1. Runnable 인터페이스를 구현한 인스턴스 생성
2. Thread 인스턴스 생성
3. start 메소드 호출
예제코드1
class Solution {
final static ThreadLocal<Integer> threadLocal = new ThreadLocal<>();
public static void main(String[] args) {
Runnable task = () -> {
threadLocal.set(1);
int num1 = 10;
int num2 = 20;
String ctName = Thread.currentThread().getName();
System.out.println(MessageFormat.format("num1 + num2 = {0} from {1} and thread local value is {2}", num1 + num2, ctName, threadLocal.get()));
};
threadLocal.set(2);
Thread t = new Thread(task);
t.start();
System.out.println(MessageFormat.format("End from {0} and thread local value is {1}", Thread.currentThread().getName(), threadLocal.get()));
}
}
End from main and thread local value is 2
num1 + num2 = 30 from Thread-0 and thread local value is 1
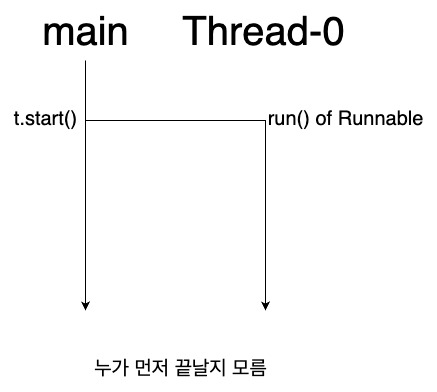
- 정의한 task를 전달하면서 Thread 객체를 생성하는 부분(밑에서 3번째 라인)은 JVM에게 쓰레드 생성을 위한 준비과정을 요청하는 부분이며 실제 쓰레드를 생성하지 않는다.
- 실제 쓰레드 생성과 실행은 start() 메소드에서 진행된다.
- 두 쓰레드 중 누가 먼저 끝날지는 알 수 없다. 코어의 상황과 Concurrency가 어떻게 발생할지 모르기 때문이다.
예제코드2
class Task extends Thread {
final static ThreadLocal<Integer> threadLocal = new ThreadLocal<>();
@Override
public void run() {
threadLocal.set((int) (Math.random() * 1000));
int num1 = 10;
int num2 = 20;
String ctName = Thread.currentThread().getName();
System.out.println(MessageFormat.format("num1 + num2 = {0} from {1} and thread local value is {2}", num1 + num2, ctName, threadLocal.get()));
}
}
class Solution {
public static void main(String[] args) throws Exception {
Task t1 = new Task();
Task t2 = new Task();
t1.start();
t2.start();
}
}
num1 + num2 = 30 from Thread-1 and thread local value is 251
num1 + num2 = 30 from Thread-0 and thread local value is 40
- 위 코드는 예제코드1과 완전히 동일하다. Thread 클래스는 Runnable을 구현하고 있기 때문이다.
예제코드3
class Solution {
public static void main(String[] args) throws InterruptedException {
Runnable task = () -> {
System.out.println(MessageFormat.format("current thread: {0}", Thread.currentThread().getName()));
};
Thread t1 = new Thread(task);
Thread t2 = new Thread(task);
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println(MessageFormat.format("current thread: {0}", Thread.currentThread().getName()));
}
}
current thread: Thread-1
current thread: Thread-0
current thread: main
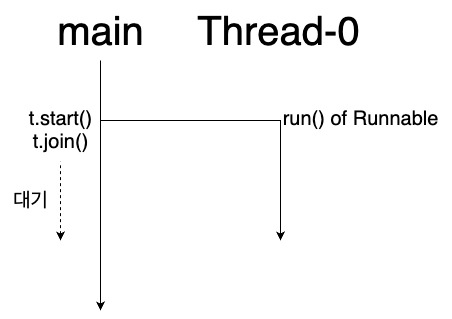
- join()은 자식 쓰레드가 종료되기를 기다린다. 따라서 가장 아래 출력문이 가장 마지막에 실행된다.
- 참고: main 쓰레드가 먼저 종료되더라도 다른 쓰레드의 실행에는 영향이 없다. 쓰레드들이 실행된 후 추가적으로, 동기적으로 실행할 코드가 있을 경우 join을 사용한다.
Race Condition
예제코드4
class Counter {
int count = 0;
public void addOne() {
count++;
}
public void subOne() {
count--;
}
}
class Solution {
public static Counter counter = new Counter();
public static void main(String[] args) throws InterruptedException {
Runnable task1 = () -> {
for (int i = 0; i < 1000; i++)
counter.addOne();
};
Runnable task2 = () -> {
for (int i = 0; i < 1000; i++)
counter.subOne();
};
Thread t1 = new Thread(task1);
Thread t2 = new Thread(task2);
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println(MessageFormat.format("count: {0}", counter.count));
}
}
count: 285
- 위 코드는 실행할 때마다 값이 다르다. 값의 범위가 음수부터 양수까지 다양하게 출력된다.
- 공유자원 count 필드에 동기화가 되어있지 않기 때문이다.
문제의 원인
count++ 또는 count-- 의 실질적인 처리 과정은 해당 메소드(run)에서 Heap 메모리에 있는 공유자원 count 값을 CPU 레지스터로 가져와 저장한 뒤, ++ 또는 -- 연산을 진행하고 다시 Heap메모리에 write하는 과정으로 진행된다. 이는 ++, -- 연산에만 해당되는 내용은 아니다. CPU가 연산을 처리하기 위해서는 레지스터의 값을 사용해야 하기 때문에, 그 외 모든 연산에서 적용된다.
예시) Concurrency에 의한 문제 발생
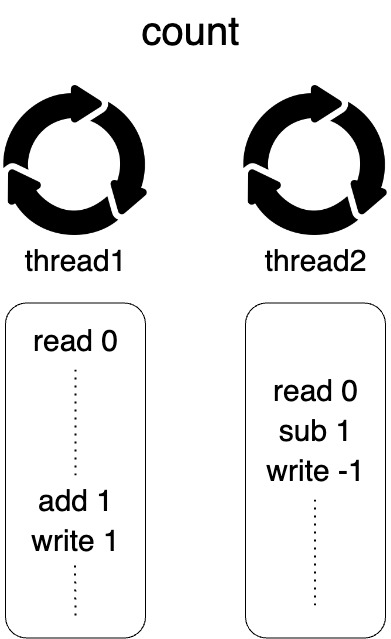
- 한 쓰레드가 실행 중에 Concurrency에 의하여 count 변수를 읽어온 상태에서 stop되고 다시 실행을 재개할 때, count 변수의 값은 갱신되어 있을 수 있다.
- 즉, 해당 쓰레드가 stop되기 전에 읽고 레지스터에 저장해둔 값과 다시 재개되었을 때의 실제 count 변수 값이 다를 수 있다는 것이다.
- 이러한 문제는 Single Core 상황에서 더 심하게 발생할 것이다.
쓰레드 동기화
1. synchronized method
예제코드5
class Counter {
int count = 0;
synchronized public void addOne() {
count++;
}
synchronized public void subOne() {
count--;
}
}
class Solution {
public static Counter counter = new Counter();
public static void main(String[] args) throws InterruptedException {
Runnable task1 = () -> {
for (int i = 0; i < 1000; i++)
counter.addOne();
};
Runnable task2 = () -> {
for (int i = 0; i < 1000; i++)
counter.subOne();
};
Thread t1 = new Thread(task1);
Thread t2 = new Thread(task2);
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println(MessageFormat.format("count: {0}", counter.count));
}
}
- 위와 같이 addOne()과 subOne() 메소드에 각각 'synchronized' 키워드를 붙이면 두 메소드가 동시에 실행되는 것을 방지한다.
- 즉, addOne()이 모두 완료될 때까지 subOne()이 실행되지 않고 대기하며 addOne()이 완료되었을 때 subOne()이 실행될 수 있다.
- synchronized 메소드의 주의할 점은 메소드의 전체 블록에 lock이 걸리기 때문에 메소드의 코드가 길다면 성능 저하 문제가 크게 발생할 수 있다는 점이다. 실행시간이 긴 메소드에 대해 synchronzied 메소드로 선언하면 해당 메소드가 모두 끝나기 전까지 다른 synchronized 메소드가 실행될 수 없기 때문이다. 따라서 synchronzied 메소드는 실행시간 자체가 짧은 메소드에 한정하여 선언해야 한다.
2. synchronized block
예제코드6
lass Counter {
int count = 0;
public void addOne() {
synchronized(this){
count++;
}
}
public void subOne() {
synchronized(this){
count--;
}
}
}
class Solution {
public static Counter counter = new Counter();
public static void main(String[] args) throws InterruptedException {
Runnable task1 = () -> {
for (int i = 0; i < 1000; i++)
counter.addOne();
};
Runnable task2 = () -> {
for (int i = 0; i < 1000; i++)
counter.subOne();
};
Thread t1 = new Thread(task1);
Thread t2 = new Thread(task2);
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println(MessageFormat.format("count: {0}", counter.count));
}
- synchronized block을 사용하면 해당 특정 block에 대해서만 lock을 설정할 수 있다.
- 메소드의 실행시간이 긴 경우에 대해서는 synchronzied 메소드를 선언하는 것은 좋지 않다. 이 경우 동기화가 필요한 부분에만 block을 지정하여 synchronzied를 선언하면 된다.
- 위처럼 필요한 부분에만 synchronzied 블록을 지정하면 해당 블록을 실행하는 동안에는 다른 synchronzied 블록, 메소드가 실행될 수 없다. 위 예시로 설명하자면 addOne()의 synchronzied 블록이 실행되는 도중에는 subOne()의 synchronzied 블록이 실행될 수 없다.
- synchronzied (this)에서 this는 동기화시킬 대상에 대한 인스턴스이다. 위 예시에서는 count 변수 하나에 대한 동기화이므로 this를 지정했으며 만약 동기화해야 할 변수가 추가적으로 더 있고 동기화 대상이 될 메소드 그룹이 2가지 이상이라면 인스턴스의 이름을 지정하면 된다.
쓰레드를 생성하는 더 좋은 방법
쓰레드 풀 모델(Thread Pool Model)
1. 쓰레드 풀에 작업 처리 요청
2. 쓰레드 풀에서 쓰레드 하나를 자동으로 할당하여 작업 처리
3. 작업 완료 후 쓰레드는 풀에 반환
- 위 실습에서 사용했던 방법은 쓰레드가 작업을 모두 완료하면 자동으로 소멸되는 과정을 거친다. 하지만 쓰레드 풀에서는 작업 완료 후 쓰레드 풀에 반환되어 재사용될 수 있다는 장점이 있다.
- 자바에서는 한 번의 메소드 호출만으로 쓰레드 풀과 쓰레드들을 만드는 라이브러리를 제공한다.
장점
- 쓰레드 생성과 소멸에 소요되는 오버헤드가 크다. 하지만 쓰레드 풀 모델은 이러한 과정이 불필요하게 된다.
- 작업의 특성상 여러 개의 쓰레드를 사용하는 경우가 많은데, 이 경우 여러 쓰레드들을 모두 만들 필요가 없다. 따라서 작업에 대한 응답 시간이 더 빨라질 수 있다.
예제코드7
class Solution {
public static void main(String[] args) {
Runnable task = () -> {
System.out.println("this task is executed by " + Thread.currentThread().getName());
};
ExecutorService exsvc = Executors.newSingleThreadExecutor();
exsvc.submit(task);
exsvc.submit(task);
System.out.println("End");
exsvc.shutdown();
}
}
End
this task is executed by pool-1-thread-1
this task is executed by pool-1-thread-1
- Executors.newSingleThreadExecutor() 에서 쓰레드 풀과 쓰레드 1개를 생성한다.
- Runnable을 구현하여 작업을 정의하고 submit 메소드만 호출하면 작업이 쓰레드 풀에 있는 쓰레드에 할당되어 처리된다.
- 쓰레드 풀이 Single Thread 기반이기 때문에 작업을 여러 번 submit 하면 submit된 순서대로 처리되며 모든 작업한 하나의 쓰레드에서 처리된다. (출력 결과 확인)
- shutdown 메소드를 통해 쓰레드 풀과 쓰레드를 모두 소멸시킨다. shutdown 메소드가 호출되었더라도 처리중인 작업이 있다면 모두 완료한 뒤 소멸된다.
cf. Executor, Executors
일반적으로 Java에서 Executor는 Runnable을 구현한 task를 실행시키는 존재이며 프레임워크 개념으로 사용된다. 이는 task 자체를 의미하는 Runnable과 이를 실행하기 위한 쓰레드에 대한 설정(예를 들면 스케줄링 등)을 분리하기 위해 등장했다. Executor를 사용함으로써 'new Thread(new RunnableTask()).start()'와 같이 직접 명시적으로 Thread를 생성하지 않고 Execute의 execute 메소드를 사용한다.
Executors는 Executor, ExecutorService에 대한 Factory 및 Util 메소드를 제공한다.(ExecutorService는 Executor를 상속함) 예를 들어, 위 코드와 같이 Executors를 통해 쓰레드 풀을 제공받고 이를 ExecutorService 참조형으로 관리할 수 있다.
cf. ExecutorService
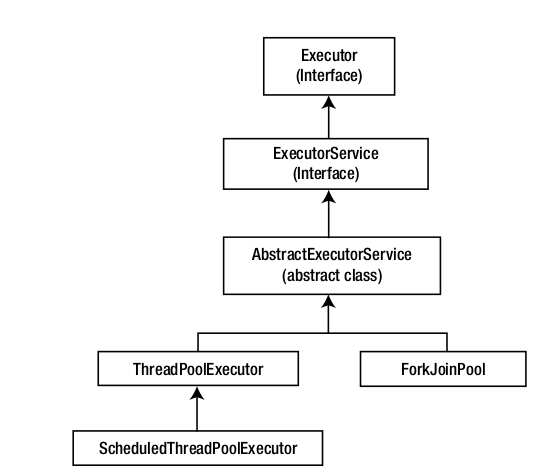
ExecutorService는 쓰레드의 전체적인 라이프사이클을 관리한다. Executor는 Runnable 작업만 실행하지만 ExecutorService는 Executor를 상속하여 이 기능을 확대하는데, 대표적으로 Future 객체를 반환함으로써 Callable task를 실행시킨다. (Callable은 아래 참고)
ExecutorService의 대표적인 구현체로 ThreadPoolExecutor가 있다. 이는 Task Queue와 Thread Pool을 가지는데, 새로운 task가 등록되었을 때 Thread Pool에 쓰레드가 남아 있다면 이를 활성화 시키고 그렇지 않다면 Queue에 작업을 적재한다. 쓰레드가 작업을 마치고 Pool에 반환되면 Queue에 작업이 남아 있는지를 확인하고 있다면 처리한다.
쓰레드 풀 유형
1. newSingleThreadExecutor()
- Pool 안에 하나의 쓰레드만 생성하고 유지한다.
2. newFixedThreadPool(개수)
- 인자로 전달한 개수만큼 쓰레드를 생성하고 유지한다.
- 코어의 수를 고려하여 코어의 수/2 정도로 할당할 수 있다.
3. newCachedThreadPool()
- Pool 안의 쓰레드의 수를 '작업의 수에 맞게' 유동적으로 관리한다.
Callable과 Future
- Runnable의 run() 메소드는 반환형이 void이다. 만약 자식 쓰레드가 작업을 완료하고 결과값을 부모 쓰레드에게 주고 싶은 경우엔 Runnable로 해결할 수 없다.
- Callable의 call 메소드는 '제네틱 타입'의 반환형을 가짐으로써 반환형을 결정할 수 있고 작업 완료 결과를 부모 쓰레드에게 넘길 수 있다.
예제코드8
class Solution {
public static void main(String[] args) throws ExecutionException, InterruptedException {
Callable<Integer> task = () -> {
int sum = 0;
for (int i = 0; i < 10; i++)
sum += i;
System.out.println("this task is executed by " + Thread.currentThread().getName());
return sum;
};
ExecutorService exsvc = Executors.newSingleThreadExecutor();
Future<Integer> fu = exsvc.submit(task);
System.out.println("result : " + fu.get());
exsvc.shutdown();
}
}
this task is executed by pool-1-thread-1
result : 45
- Runnable 기반의 쓰레드와 Callable 기반의 쓰레드는 반환 값 유무 외에는 크게 차이가 없다.
- Callable 기반의 쓰레드가 반환하는 값을 받아줄 때에는 Future 객체를 사용한다.
- main 쓰레드의 fu.get() 부분에서 blocking되어 작업이 끝나기를 기다리게 된다.
synchronized를 대신하는 ReentrantLock
예제코드9
class Solution {
ReentrantLock criticalObj = new ReentrantLock();
void method1() {
criticalObj.lock();
// 한 순간에 한 쓰레드에 의해서만 실행되는 영역
criticalObj.unlock();
}
}
- ReentrantLock을 사용하면 보다 편리하게 Lock을 사용할 수 있다.
- ReentrantLock의 lock()과 unlock()을 이용하여 해당 구역을 특정 시점에 하나의 메소드에서만 실행되도록 강제한다.
장점
- lock과 unlock은 여러 개의 메소드에 걸쳐 실행될 수 있다. 하지만 lock, unlock의 범위는 한 인스턴스이다.
- ReentrantLock 인스턴스를 2개 이상 만들어서 critical section을 여러 개로 만들 수도 있다.
주의할 점
- unlock을 하지 않고 빠져나가면 문제가 될 수 있다.
- 따라서 아래와 같이 try ~ finally로 묶어 사용하기를 권고하고 있다.
예제코드10
class Solution {
ReentrantLock criticalObj = new ReentrantLock();
void method1() {
criticalObj.lock();
try {
// 한 순간에 한 쓰레드에 의해서만 실행되는 영역
} finally {
criticalObj.unlock();
}
}
}- unlock이 생략되는 것을 방지하기 위한 권고 사항이다.
'[ 백엔드 개발 ] > [ Java,Kotlin ]' 카테고리의 다른 글
| [JAVA] 인터페이스의 발전 과정 (0) | 2022.04.16 |
|---|---|
| [java] Collection 인스턴스 동기화 (0) | 2022.04.07 |
| <추천글>[JAVA] Tim Sort 알고리즘 / 지역성의 원리 (0) | 2022.01.25 |
| [java] HashMap 동작 과정, String의 해쉬 값 (0) | 2022.01.11 |
| [java] Thread Synchronization (Monitor) (0) | 2021.12.28 |
- Total
- Today
- Yesterday
- 우분투
- go
- db
- spring
- Non-Blocking
- golang
- ci/cd
- rolling update
- Java
- kafka
- 코틀린
- container
- 카프카
- CICD
- Stream
- Linux
- Controller
- ubuntu
- docker
- argocd
- helm
- 컨트롤러
- 쿠버네티스
- Kubernetes
- K8s
- LFCS
- GitOps
- jvm
- RDB
- github actions
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |