
티스토리 뷰
웹 서비스 가용성(Availability)
가용성이란 서버와 네트워크 등의 시스템이 정상적으로 사용 가능한 정도를 의미한다. 즉, 서비스가 다운되지 않고 정상적으로 유지할 수 있는 능력을 의미한다.
cf. High Avaliability(HA)
고가용성 시스템을 위한 대표적인 방법으로 시스템 확장과 시스템 이중화가 있다. (Scale Up/Down, Scale Out/In)
성능테스트 (Performance Test)

성능테스트는 시스템의 '고가용성을 위해' 병목지점과 같은 성능 이슈를 찾는 테스트이며 성능테스트의 대표적인 유형으로 '부하테스트(load test)'와 '스트레스 테스트(stress test)'가 있다. 성능 테스트는 좀 더 추상적인 개념이다.
1) 부하테스트 (Load Test)
- 부하 테스트는 '임계 값 한계에 도달할 때까지' 시스템의 부하를 지속적으로 지속적으로 증가시켜 시스템을 테스트하는 성능 테스트의 한 유형이다.
2) 스트레스 테스트 (Stress Test)
- 스트레스 테스트는 시스템 자원에 감당가능한 수준 이상의 '과잉 작업'을 통해 과부하를 주어 시스템을 무너뜨리는 시도를 한다. 이를 통해 시스템이 과부하 상태에서 어떤 동작을 보이는지를 확인한다.
- 보통 시스템의 과부하 상태에서 시스템이 '어떻게 정상적으로 복구되는지' 모니터링하는 것을 목적으로 한다.
- 스트레스 테스트 방식 중에 사용자의 수를 천천히 증가시켜 시스템의 지속 가능한 시간을 테스트할 경우 이를 흡수 테스트라고 한다. 마찬가지로 사용자의 수를 한 번에 증가시켜 시스템의 상태를 확인하는 경우 이를 스파이크 테스트(Spike Test)라고 한다.
cf. 성능에 문제를 줄 수 있는 대표적인 요소
- 시스템 자원(CPU, Memory, Disk I/O, 네트워크 등) 사용 급증으로 인한 성능 저하
- 급증한 DB I/O로 인한 blocking (JDBC는 기본적으로 block I/O이다.)
- 부적절한 DB 커넥션 풀 설정
- DBMS 단에서 급증한 request로 인한 DB Lock
- 동시간대에 여러 배치 작업 발생
성능판단을 위한 대표적인 지표
1) Throughput(처리량)
- 시간당 처리량을 의미한다.
- 처리량은 좀 더 추상적인 의미이며 처리량을 수치로 나타내는 세부 항목으로 TPS(Transaction per seconds), RPS(Request per seconds) 등이 있다.
- 세부항목들은 처리량을 어떻게 정의하냐의 차이이며 보통 1초 당 처리량을 의미하는 용도로 사용된다.
- 처리량이 클수록 더 긍정적인 값이다.
2) Latency(지연시간)
- 지연시간은 클라이언트로 요청을 받고 응답을 하기까지의 전체적인 시간으로 낮을수록 좋다.
- 클라이언트를 누구로 설정하냐에 따라 아래와 같이 여러 세부항목들이 있다.
1) 실제 유저를 클라이언트로 생각하면 유저가 웹 시스템에서 특정 요청을 하고 이에 대한 응답이 화면에 보이기까지의 시간을 의미한다.
2) 웹 브라우저와 같은 클라이언트 프로세스를 클라이언트로 생각하면 백엔드 프로세스 입장에서 요청을 받고 응답을 주기까지의 시간을 의미하게 된다.
3) 백엔드 프로세스를 클라이언트로, DBMS를 서버로 생각하면 DBMS가 요청을 받고 응답하기까지의 시간을 의미한다.
대표적으로 사용되는 성능지표 세부항목
1. Throughput - TPS(Transaction Per Second)
- 초당 처리량을 의미하며 유저수를 기준으로 하는 Throughput의 세부항목 중 하나이다.
- Transaction는 DB트랜잭션 의미가 아니라 비즈니스 트랜잭션이다. 물론 DBMS에서의 TPS는 초당 DB트랜잭션 수를 의미한다.

- 유저 수에 따라 TPS는 지속해서 증가하다가 더 이상 증가하지 않고 유지되는 시점을 Saturation Point(포화지점)이라고 한다.
- 만약 스트레스 테스트를 통해 포화 지점이 지난 후 TPS가 떨어진다면 튜닝이 필요한 시스템이다.
- 포화지점은 '초당 처리할 수 있는 Transaction의 수가 한계에 도달했고 그때부터 사용자가 증가하면 Latency가 증가한다는 것'을 의미하므로 포화지점을 해당 서버가 감당할 수 있는 한계 지점이 된다.
2. Latency - Average Resonse Time(평균 응답 시간)
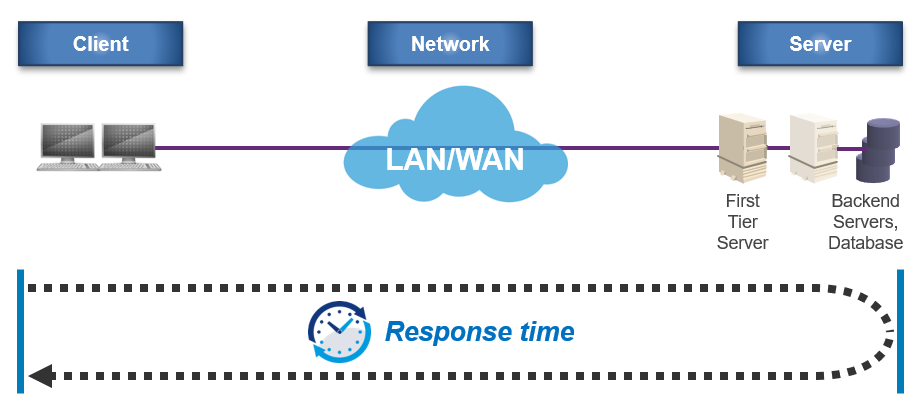
- 위 그림은 Client PC를 Average Response Time 계산의 시작점으로 보았을 때를 나타내며 요청한 시점부터 서버로부터 그 결과에 대한 응답을 받아서 사용자 화면에 디스플레이할 때까지 소요된 총시간의 평균이다.
- Response Time = Client Time + Network Time + Server Processing/Sending Time
- 그 외, Mean Test Time(평균 테스트 시간) 등의 Latency 지표들이 있다.
더 좋은 성능 판단 기준 예시
특정 웹 시스템에 아래와 같이 간단한 페이지가 있다.
1) 메인 페이지
2) 로그인 페이지
3) 상품 목록 페이지
4) 상품 상세 페이지
5) 주문 페이지
만약 위 서비스의 '목표 TPS를 100', '각 페이지마다의 부하'를 아래와 같이 정해주었다고 가정하자.
1) 메인 페이지: 부하 비율을 60%로 설정 (가장 많이 사용되므로)
2) 로그인 페이지: 부하 비율을 5%로 설정
3) 상품 목록 페이지: 부하 비율을 20%로 설정
4) 상품 상세 페이지: 부하 비율을 10%로 설정
5) 주문 페이지: 부하 비율을 5%로 설정
똑같은 기능을 제공하면서 설계나 구현을 달리 한 두 서비스가 있다고 생각해 보고 평균 응답 시간이 아래와 같이 나왔다고 가정하면,
| -1- | -2- | |
| 메인 페이지 | 1초 | 3초 |
| 로그인 페이지 | 5초 | 3초 |
| 상품 목록 페이지 | 1초 | 3초 |
| 상품 상세 페이지 | 3초 | 3초 |
| 주문 페이지 | 5초 | 3초 |
| -평균- | 3초 | 3초 |
평균 응답 시간이 두 시스템에서 모두 같더라도 더 좋은 서비스라고 판단하는 것은 비즈니스 관점에 따라 달라진다. 하지만 일반적으로 메인 페이지와 상품 목록 페이지를 가장 많은 유저들이 접속하기 때문에 1번 서비스가 더 좋은 서비스라고 생각하는 사람이 많을 것이다. 즉, 비즈니스에 대한 이해가 있어야 더 좋은 설계를 할 수 있다.
성능 테스트 도구: nGrinder
nGrinder는 Java기반으로 작성된 성능 테스트 툴이며 1.6 이상의 JDK가 필요하다. Groovy 기반의 test script를 지원하여 비교적 쉽게 script를 작성할 수 있다는 장점이 있다.
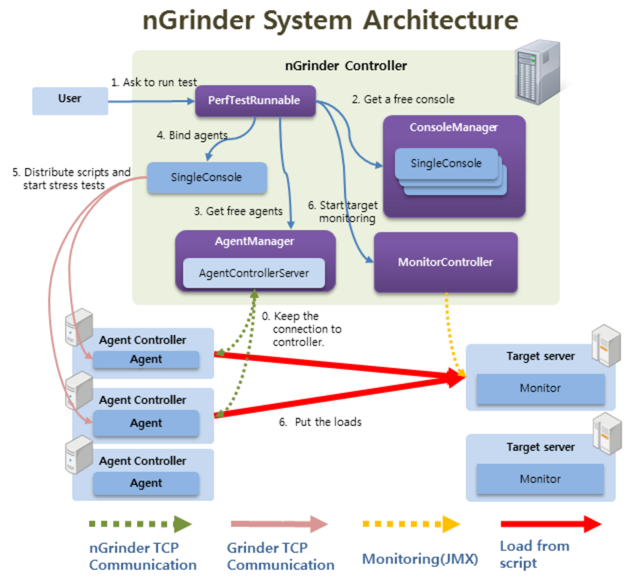
1. 구성 요소
| Controller | 웹 기반의 GUI 시스템으로 테스트 전반적인 작업이 이 Controller 에 의해서 작동한다. 테스트 스크립트와 성능 테스트를 관리할 수 있다. |
| Agent | Controller의 명령어를 받아 Target 머신에 프로세스와 쓰레드를 실행시켜 부하를 발생시키는 '가상 유저 제너레이터'이다. 여러개의 노드에 설치되어서 Controller의 signal에 따라서 일시에 부하를 발생시킨다. |
| Target | 테스트를 하기위한 타겟 머신(노드)이다. 일반적으로 테스트를 하려는 서버가 Target 이다. |
Controller와 Agent를 각 환경에 실행시켜야 한다.
- Conctroller war 파일: https://github.com/naver/ngrinder/releases
- Controller Image 파일: https://hub.docker.com/r/ngrinder/controller/
- Agent Image 파일: https://hub.docker.com/r/ngrinder/agent
2. 실행 (컨테이너 기반)
docker-compose.yaml
version: '2.13'
services:
ngrinder-controller:
image: ngrinder/controller:3.5.5-p1
container_name: ngrinder-controller
ports:
- "80:80"
- "16001:16001"
- "12000-12009:12000-12009"
volumes:
- ./ngrinder/controller:/opt/ngrinder-controller
ngrinder-agent:
container_name: ngrinder-agent-1
image: ngrinder/agent:3.5.5-p1
command: ["ngrinder-controller:80"]
- nGrinder 최신 버전을 사용했을 때 그루비 스크립트 검증 단계에서 알 수 없는 문제가 발생하여 다운그레이드 후 실행했다.
- 테스트할 서버와 Controller를 같은 노드에 설치할 것이기 때문에 docker compose를 통해 Controller와 Agent를 실행시켰다.
- 'http://[Controller호스트IP]:80'을 통해 Controller에 접속하여 admin/admin으로 초기 로그인한다.
- docker 로그에서 'Connected to agent controller server at /172.19.0.3:16001'를 확인하여 Agent가 Controller에 연결된 것을 확인하자. 또는 에이전트 관리 탭에 연결된 에이전트 목록이 보이지 않으면 문제가 생긴 것이다.
cf. 컨테이너 사양 변경
- 성능 테스트 중 Vuser수가 너무 크면 'agent is about to die due to lack of free memory.' 문구가 나오면서 Agent가 죽을 수 있다. Vuser를 늘리고 크게 늘리고 싶으면 컨테이너 사양을 조절하여 테스트해야 한다.
3. Test Script 작성

- 스크립트 탭으로 이동하고 만들기 클릭.
- Script Name 및 테스트할 API 주소 입력
- 스크립트 생성 후 '검증'을 눌러 스크립트에 문제가 없는지 확인
4. 성능 테스트 생성
테스트할 Spring 애플리케이션의 JVM 설정 정보
$ sudo jhsdb jmap --heap --pid [Java Process ID]- JVM: 17 LTS
- GC 쓰레드: 10개 (Garbage-First (G1) 기반)
- MaxHeapSize: 2034237440 (1940.0MB)
cf. 그 외 WAS 설정
- 톰캣 기본 설정 기반(NIO기반 톰캣 9 버전, 기본 워커 쓰레드 200개)
- HikariCP 기본 설정 기반(maximumPoolSize: 10, connectionTimeout: 30 sec)
테스트 환경 호스트 정보
- OS: Ubuntu 20.04 LTS
- Memkory: 16GB
- Processor: i5-11500 (전체 코어 12)
- Storage: 1TB SSD
첫 테스트부터 Vuser를 과하게 2000으로 주었더니 시스템이 먹통이 되었다. 그래서 Vuser를 10부터 시작하여 점차 늘려가는 방식으로 테스트를 진행했다.
성능 테스트 설정
- Agent: 에이전트 개수. 현재 1개 사용 중.
- Vuser per agent: 테스트할 사용자 수 (각 테스트마다 늘려가며 진행)
- Duration: 테스트할 기간 (10분으로 고정)
- Ramp-Up: 갑작스러운 서버 부하 방지 설정 (현재 테스트에선 적용하지 않을 예정)
테스트 결과
아래는 Vuser가 10, 30, 50, 99일 때를 각각 테스트한 결과이다. TPS는 높을수록, Mean Test Time(Average Response Time)은 낮을수록 긍정적인 값을 의미하기 때문에 성능 결과 값을 'TPS / Mean Test Time'로 판단했다.
case1) Vuser: 10
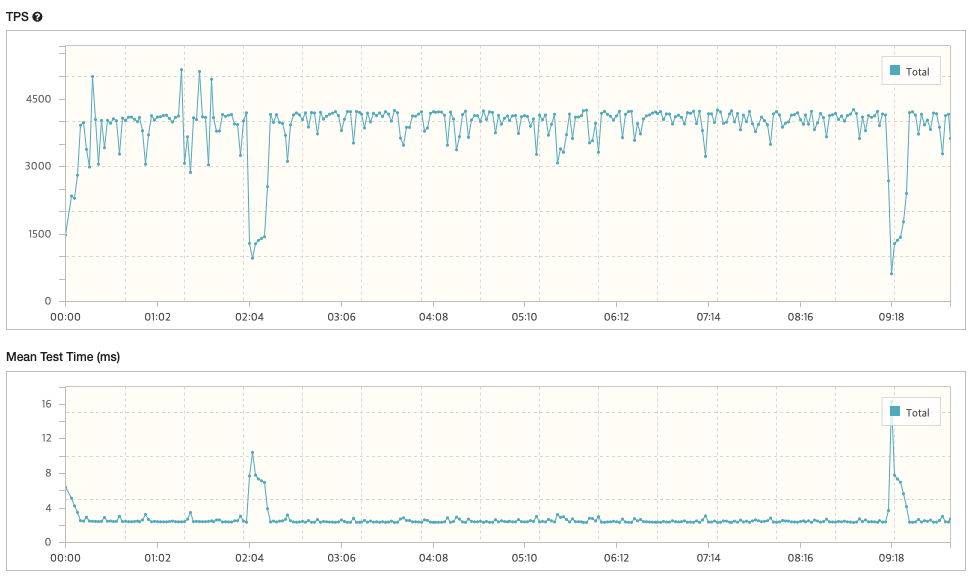
- TPS: 3,854.1
- Peak TPS: 5,141
- Mean Test: Time
- Mean Test Time: 2.55 ms
- Executed Tests: 2,305,579
- Successful Tests: 2,305,579
- Errors: 0
* 결과: TPS / Mean Test Time = 3,854.1 / 2.55 = '1511.4'
case2) Vuser: 30
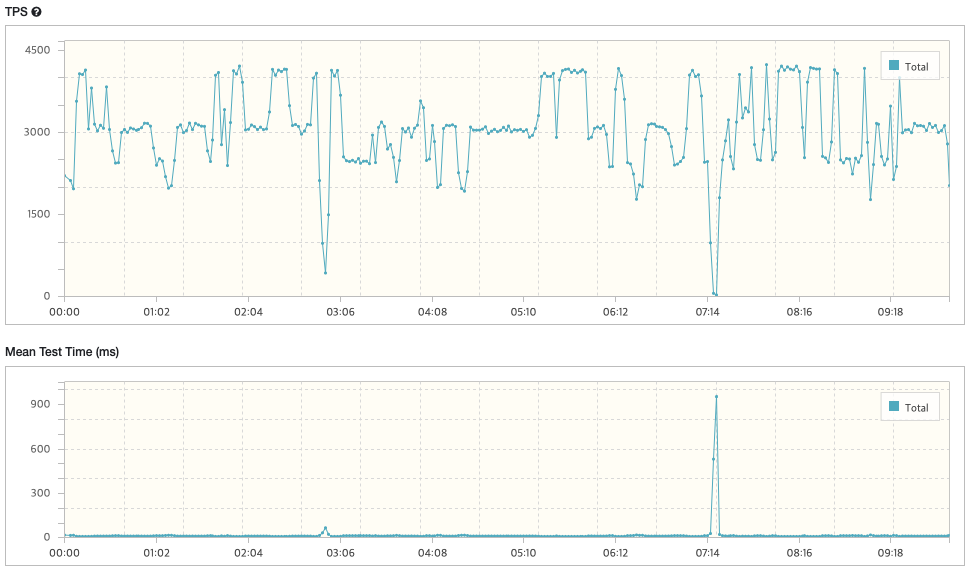
- TPS: 3,047.7
- Peak TPS: 4,226
- Mean Test Time: 9.80 ms
- Executed Tests: 1,823,199
- Successful Tests: 1,823,199
- Errors: 0
-> 유저 수를 10에서 30으로 늘렸더니 TPS(Throughput, 처리량)가 비교적 줄어들었고 불안정한 상태로 변경되었음을 확인
-> 또한 응답시간 역시 3배 이상 늘어났음을 확인
* 결과: TPS / Mean Test Time = 3,047.7 / 9.80 = '310.9'
case3) Vuser: 50
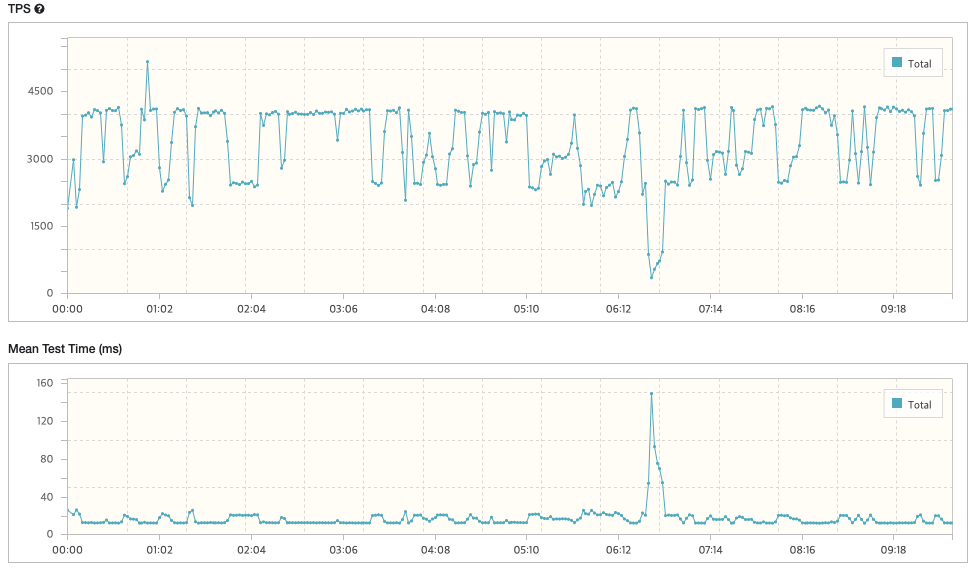
- TPS: 3,338.0
- Peak TPS: 5,158
- Mean Test Time: 14.93 ms
- Executed Tests: 1,996,759
- Successful Tests: 1,996,759
- Errors: 0
* 결과: TPS / Mean Test Time = 3,338 / 14.93 = '223.5'
-> TPS는 Vuser가 30일 때보다 약간 늘었지만 응답시간은 크게 증가한 것을 확인할 수 있다. 그러나 테스트 결과 점수는 더 낮아졌으므로 성능은 더 나빠졌음을 추측할 수 있다.
case4) Vuser: 99
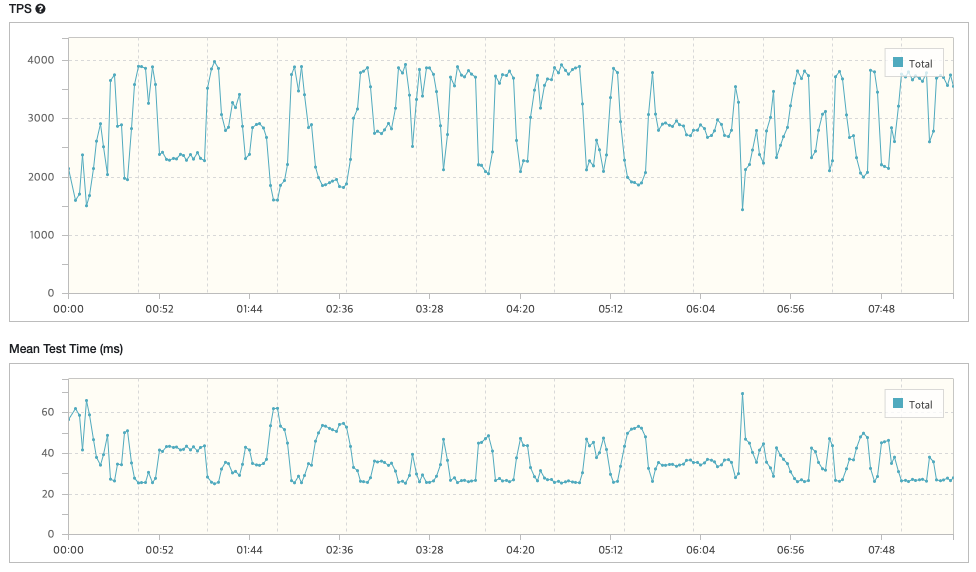
- TPS: 2,914.6
- Peak TPS: 3,963
- Mean Test Time: 33.92 ms
- Executed Tests: 1,488,671
- Successful Tests: 1,488,671
- Errors: 0
* 결과: TPS / Mean Test Time = 2,914.6 / 33.92 = '85.9'
병목지점 개선
- 최소 평균 TPS 목표치를 3000으로 설정할 경우, 유저가 99일 때를 최대유저수로 생각해 볼 수 있다.
- Vuser가 99가 되었을 때 처리량이 2000대로 낮아진 것으로 결과를 보다 개선하기 위해 아래와 같이 병목지점을 추측했다.
1. 병목지점 추측
- 현재 테스트한 API는 게시글 단건 조회에 대한 API이다.
- 데이터베이스는 MySQL8을 사용했으며 게시글 데이터는 정확히 17만 개가 들어가 있다.
- 아래와 같이 병목지점이 될 만한 케이스를 3가지 추측했다.
1) DB Access 지점(JDBC의 Blocking I/O)
- HikariCP를 사용했으며 주요 성능 지표인 커넥션 풀 최대/최소 크기(minimum-idle, maximum-pool-size)와 커넥션의 lifetime(max-lifetime), 커넥션을 기다릴 최대 시간(connection-timeout)이 적절했기에 병목지점에 영향을 주는 요소에서 제외
2) DB 인덱스 재정렬 발생
- 해당 API의 트랜잭션에서 접근하는 테이블을 살펴본 결과값을 변경시키는 요소 중 인덱스가 설정된 컬럼은 없음. 따라서 병목지점에 영향을 주는 요소에서 제외.
3) DB Lock으로 인한 성능 이슈
- 초기 데이터베이스 설계는 게시글의 정보를 저장하는 게시글 테이블에 게시글 조회수를 의미하는 컬럼을 두었고 이 부분이 문제가 될 수도 있다는 가능성 제기.
- 게시글이 조회될 때마다 조회수를 증가시키고 있었기 때문에 데이터 변경에 필요한 exclusive lock이 잡혀 있는 것을 원인으로 추측.
이 중에서도 '3) DB Lock으로 인한 성능 이슈'가 가장 그럴듯 하다. 이에 대한 근거는 아래와 같다.
* 근거 *
게시글이 조회될 때마다 조회수를 증가시키고 있었기 때문에 데이터 변경에 필요한 exclusive lock이 잡혀있어 같은 요청의 여러 트랜잭션들이 병렬적으로 처리할 수 없게 된다.
2. 병목지점 개선방안 - 수직 파티셔닝 및 부수효과
1) 데이터베이스 설계에서 게시글 테이블로부터 조회수를 의미하는 컬럼을 제거하고 조회수를 저장할 테이블로 분리시켰다. 이는 '게시글 정보 조회 트랜잭션'과 '게시글 조회수 업데이트 및 조회수 조회 트랜잭션'을 분리시키기 위함이다. 뿐만 아니라 게시글 단건 조회 시 유저에게 보다 빠른 응답을 주기 위해 조회수를 조회하는 API는 별도로 분리했다. 게시글 단건 조회는 동시다발적으로 계속해서 발생하는(즉, 사용 빈도가 높은) API이기 때문에 게시글 조회API만 분리한 것이다. 따라서 사용자 입장에서는 조회수를 제외한 게시글 단건 데이터를 빠르게 받아볼 수 있게 된다. 이로써 게시글 조회에 대한 트랜잭션의 read-only 설정을 true로 할 수 있게 되어 더욱 성능 향상에 도움이 되리라 생각된다.
2) 게시글 조회수 테이블의 필드는 '게시글 id'와 '조회수'로 설계했으며 게시글 id에 인덱스를 설정하여 조회수 데이터를 빠르게 가져올 수 있도록 반영했다. (게시글 조회수 테이블의 데이터는 게시글이 생성될 때 함께 생성되도록 설계했다.)
3) MySQL에서 트랜잭션의 read-only 설정을 활성화하면 shared lock까지도 배제하고 동작하는데 이는 스냅샷을 통해 빠르게 데이터를 읽어오기 때문이다. (단, 동기화가 중요한 데이터에 대해선 신중해야 함)
- cf. 트랜잭션 read-only 설정에 대한 포스팅: https://jh-labs.tistory.com/679
3. 병목지점 개선 후 테스트
case) Vuser: 99
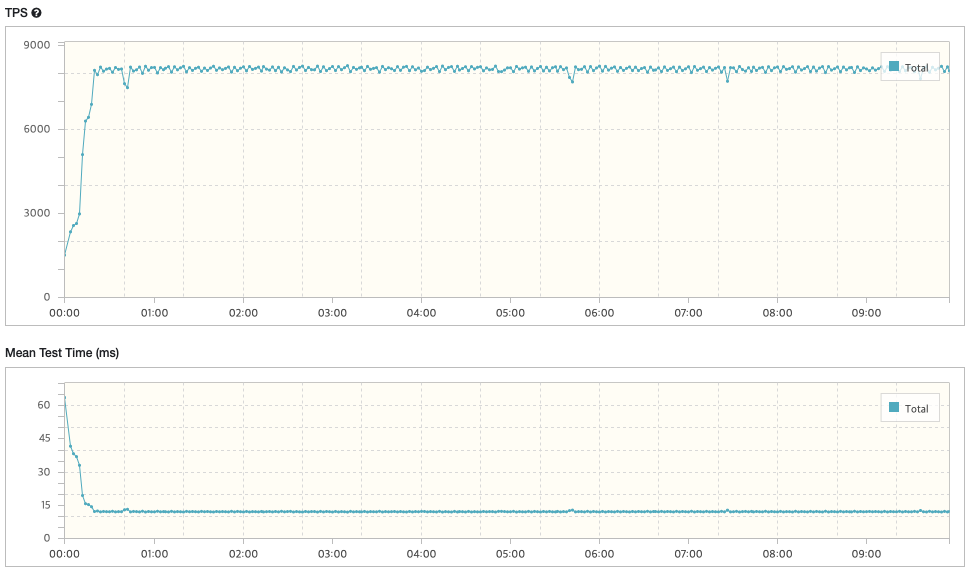
- TPS: 8,025.3
- Peak TPS: 8,273
- Mean Test Time: 12.24 ms
- Executed Tests: 4,784,048
- Successful Tests: 4,784,048
- Errors: 0
* 결과: TPS / Mean Test Time(Average Response Time) = 8,025.3 / 12.24 = '655.66'
병목지점 개선 전 Vuser=99일 때의 점수인 85.9와 비교해 보면 약 7.6배의 성능에 긍정적인 효과를 보였음을 알 수 있다.
cf. 추가적인 성능 개선 방안 (TODO)
- JVM 환경 설정 (최대 메모리 크기 등)
- HikariCP 최적화 (maximumPoolSize, connectionTimeout 등)
- 더 많은 동시접속 유저를 허용하기 위한 애플리케이션 Scale-Out
- CQRS 패턴 (read / write DB 분리)
- 서버 Scale-Up
- Redis 적용
- 쿼리 튜닝
- etc,
Reference
- nGrinder 사용법, https://ch4njun.tistory.com/266
- 성능테스트 기본 지식 이해, https://youtu.be/13xMwTTkQ30
- nGrinder docs, https://naver.github.io/ngrinder/
- nGrinder Controller war file, https://github.com/naver/ngrinder/releases
- nGrinder Controller Docker Image, https://hub.docker.com/r/ngrinder/controller/
- nGrinder Agent Docker Image, https://hub.docker.com/r/ngrinder/agent
- nGrinder 실행 방법, http://jmlim.github.io/ngrinder/2019/07/01/ngrinder-docker-setup/
- groovy syntax, http://www.groovy-lang.org/syntax.html
- Groovy test script sample, https://mingood.tistory.com/10
'[ 트러블슈팅-개선 ]' 카테고리의 다른 글
| [k8s] 도메인 lookup 에러: Pod CIDR 및 호스트 CIDR (0) | 2023.08.07 |
|---|---|
| [k8s] NodePort 접속 오류 해결 (진행중) (0) | 2022.10.17 |
| [kubernetes] kubectl Connection Refused 이슈 해결 (0) | 2022.08.26 |
| [Jenkins] Ubuntu 20.04에서 젠킨스 포트 변경하기 (0) | 2022.06.02 |
- Total
- Today
- Yesterday
- container
- Stream
- RDB
- github actions
- Kubernetes
- jvm
- ci/cd
- 카프카
- LFCS
- 코틀린
- docker
- CICD
- spring
- rolling update
- helm
- ubuntu
- Non-Blocking
- Controller
- Linux
- GitOps
- 우분투
- db
- kafka
- go
- Java
- 쿠버네티스
- 컨트롤러
- K8s
- golang
- argocd
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |