
티스토리 뷰
Balanced Tree
(불균형) 이진탐색트리의 문제점은 최악의 경우 O(N)이 발생한다는 것이다. Balanced Tree는 항상 균형을 맞추어진 상태로 유지함으로써 O(logN)의 성능을 보인다. 하지만 데이터의 삭제, 삽입, 갱신이 발생할 때 Balance를 유지하기 위한 연산이 추가로 필요하게 된다는 단점이 있다. Balanced Tree의 종류로 AVL Tree와 레드블랙트리, 2-3 Tree, 2-3-4 Tree, B Tree 등이 있다.
B-Tree는 다차원트리
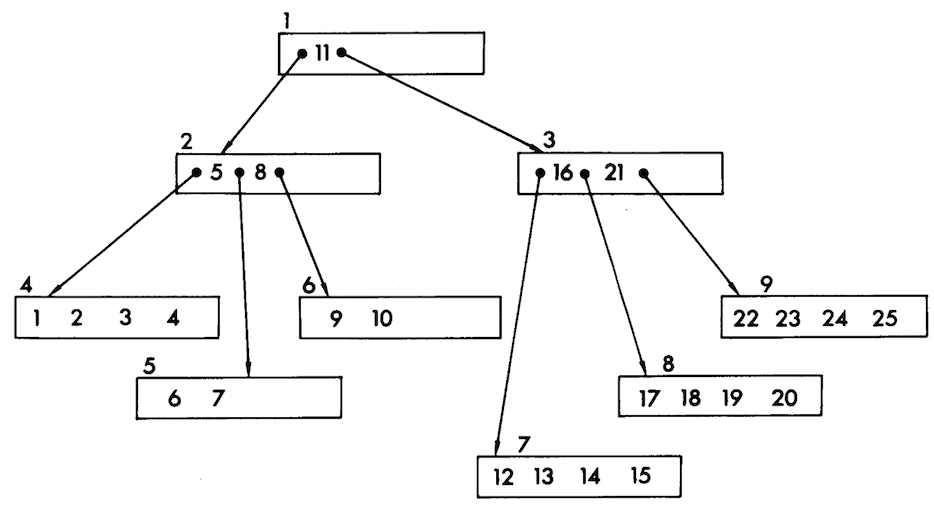
B-Tree는 Balanced Tree이면서 다차원 트리이다. 하나의 노드가 가질 수 있는 자식 노드의 개수(링크 개수)를 M이라고 했을 때 하나의 노드에 '최대' M-1개의 자료를 담을 수 있으며 이 경우 M차 다차원 트리라고 한다. 만약 4차원 트리라고 하다면 모든 노드는 자료를 1~3개까지 담을 수 있다. 이렇듯 다차원 트리는 하나의 노드에 여러 자료를 저장함으로써 큰 파일의 탐색과 갱신에 유리하며 Balanced Tree일 경우에는 최악의 경우에도 성능을 보장한다.
B Tree의 규칙
1) 정렬 상태 유지
B-Tree는 항상 반드시 '정렬'되어 있는 상태로 유지한다는 특징이 있다.
2) 노드 당 자료의 개수 제한
M차 다차원 트리에서 하나의 노드에 1개 이상, M-1개 이하의 자료를 담을 수 있지만, B-Tree에서는 하나의 노드에 최소 M/2개 이상, M-1 이하의 자료를 담아야 한다.(절반 이상은 담아야 함) 단, 루트 노드의 경우에는 예외이다. 루트노드는 최소한 2개 이상의 자식노드를 가져야 한다. 따라서 1개 이상의 자료를 가져야 한다. 예를 들어 M이 6이라면 각 노드에는 3이상 5이하의 자료를 담을 수 있다. 보통의 경우에는 M값을 홀수로 관리하는 것이 일반적이다.
cf. 정확히 M/2 개 이상을 한 노드에 담아야 하는 이유는 찾지 못했으나 아마도 B-Tree의 depth를 최소화하기 위해서가 아닐까 생각한다. 다차원트리인데 한 노드에 1개의 자료만 담는다면 다차원트리의 장점을 가져가지 못할 것이다. 특히 B-Tree는 정렬되어있다는 전제조건이 있기 때문에 정렬된 인접한 데이터를 담기에 하나의 노드에 여러개의 자료를 담는 것이 유리할 것이다.
3) leaf 노드로 가는 경로의 길이
B-Tree는 Balanced Tree이기 때문에 어떠한 leaf 노드라도 root부터 출발하는 경로를 모두 같다. (완전 균형)
B-Tree 구조
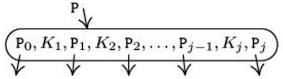
B-Tree의 각 노드에는 위와 같이 하위 노드의 주소값인 포인터와 키 값이 번갈아가며 저장되는 배열형태이며 실질적으로 시스템의 페이지 크기와 일치한다. 각 키 값은 정렬되어 있기 때문에 B-Tree를 탐색할 때에는 각 키값에 대해 순차탐색을 하거나 키의 개수가 많을 때에는 이진탐색을 하기도 한다. 하지만 해당 노드에서 원하는 키 값을 찾지 못했다면 포인터를 통해 하위 노드로 이동한다. 만약 더이상 내려갈 하위노드의 포인터를 찾지 못했다면 탐색은 실패한 것이다.
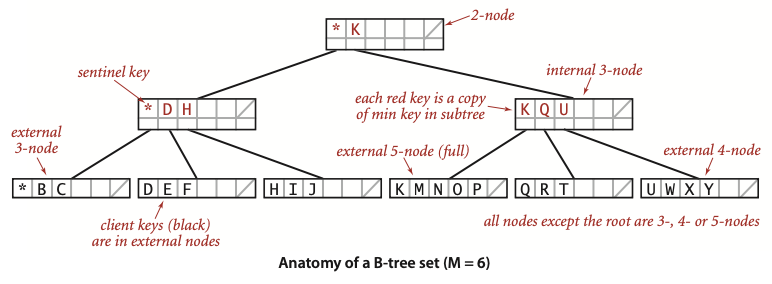
B Tree의 성능 분석
[완전균형 이진탐색트리의 시간복잡도]
다차원트리의 일종인 B Tree의 성능을 분석하기 앞서, 완전균형 이진탐색트리에서의 성능을 점근적 분석 기법을 통해 살펴보면 다음과 같다.
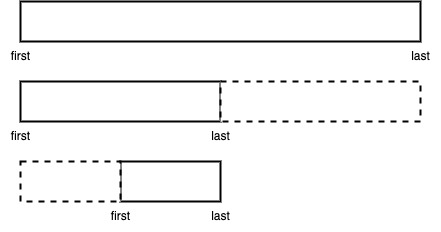
우선 완전균형 이진탐색트리라고 가정했을 때, 트리에서 탐색 대상이 되는 범위를 매 단계마다 절반 씩 줄여나간다.
첫 단계에서 절반이 버려져서
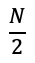
그다음 단계에서 또다시 절반이 버려지기 때문에
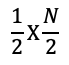
만약 k번 수행을 했다면 다음과 같은 형태가 된다.
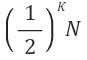
위 탐색 과정이 자료가 1개 남아 있을 때까지 반복하므로
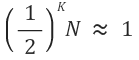
형태가 될 것이고, 양변에 2의 k승을 곱한 뒤 밑이 2인 log를 적용하면
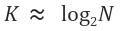
가 될 것이다. 즉, 실행 횟수 K가 곧 시간을 나타내는 성능이기 때문에 시간복잡도는
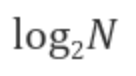
이다.
[완전균형 다차원트리의 시간복잡도]
완전균형 이진탐색트리와 마찬가지로, 오더 M인 다차원 트리에서는 각 단계마다 이전 단계의 데이터 개수의
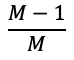
비율만큼 탐색대상에서 제외되고,
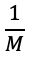
비율만큼이 남겨지게 되므로
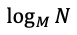
가 최종 시간복잡도가 된다. (여기서 N은 총 자료의 개수)
[B Tree의 시간복잡도]
기본적으로 로그함수에서 밑이 커질수록 Y의 증감률은 작기 때문에 로그함수의 밑이 커질수록 더 좋은 성능을 가진다고 볼 수 있다. 즉, 다차원 트리의 시간복잡도에서 Log의 밑인 M 값이 커질수록 좋은 성능을 보인다. 특히, B Tree의 경우 일반 다차원트리와는 다르게 최소한 M/2에서 최대 M-1 범위의 링크를 가져야 하기 때문에 최악의 경우에도 밑이 M/2 인 로그함수에 비례하는 성능을 보일 것이다.
따라서 B Tree의 빅-오(최악의 경우라는 가정이 포함됨)식은 다음과 같다.
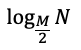
만약 모든 노드에 M-1개의 자료를 담을 경우에는 최선의 경우가 될 것(트리의 depth가 최소화)이고 이 경우의 성능은 다음과 같다.
[B Tree 성능분석 예시]
B Tree에서 노드의 크기는 가상메모리 시스템의 페이지 기법과 연관되어 있는데, 보통 디스크의 블록 크기는 8KB ~ 16KB로 B Tree에서 하나의 노드 크기인 페이지 크기와 일치한다.
페이지 크기가 8KB이고 자료 하나의 크기(여기서 자료란 하나의 키와 하나의 포인터의 조합)가 10바이트라고 가정하면 하나의 노드에 최대 819.2개의 자료를 담을 수 있다. 여기서 최악의 경우는 정확히 모든 노드가 절반의 자료를 담는 것이므로 밑이 410인 로그함수의 성능을 보일 것이다.
cf. 페이지 크기와 포인터 변수의 크기, 키의 크기가 주어졌을 때 하나의 노드에 담을 수 있는 자료의 개수
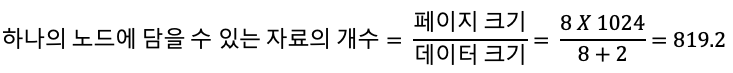
즉, 위 경우의 B Tree에서 차수는 819가 된다. 따라서 완전균형 이진탐색트리(밑이 2인 로그함수)와 차수가 819인 B Tree의 시간복잡도 (최악의 경우 밑이 410인 로그함수) 그래프는 다음과 같다.
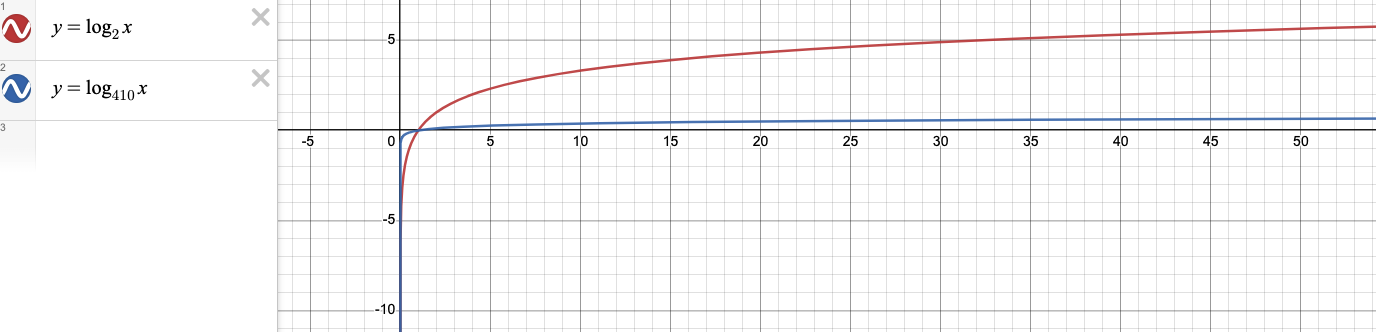
밑이 819인 로그함수는 '거의 상수에 가까운 시간'을 보이고 있음을 확인할 수 있다. 만약 데이터가 100만 건일 경우, 밑이 2인 로그함수는 20, 밑이 410인 로그함수는 2.3의 값을 가진다. 100만 건만 되어도 성능이 약 8.6배 차이 나는 것이다.
이처럼 B Tree는 '다차원트리'이면서 'Balanced 트리'라는 점에서 방대한 자료를 담고 관리하기에 최적의 성능을 보이는 자료구조임을 확인할 수 있다.
B Tree 연산
1. 삽입과정
1) 오버플로우가 발생하지 않는 경우
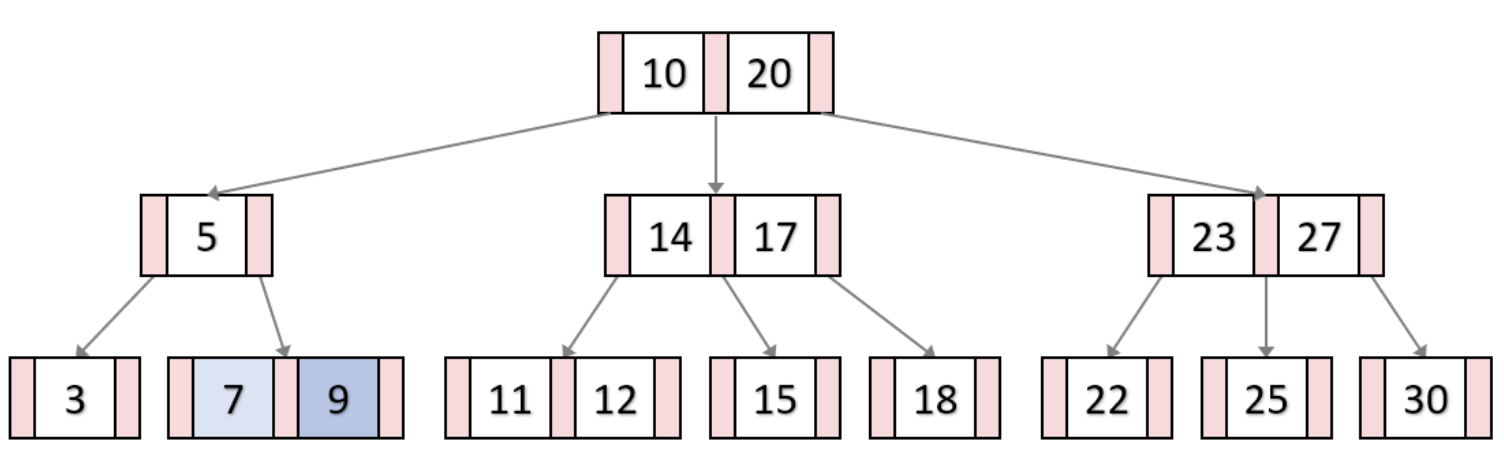
위 그림은 오더 3인 B-Tree에서 키값 9가 삽입되는 과정을 보여준다. 9가 삽입된 노드에서 오버플로우가 발생하지 않았기 때문에 분할이 발생하지 않고 정상적으로 삽입된다.
2) 오버플로우가 발생하는 경우
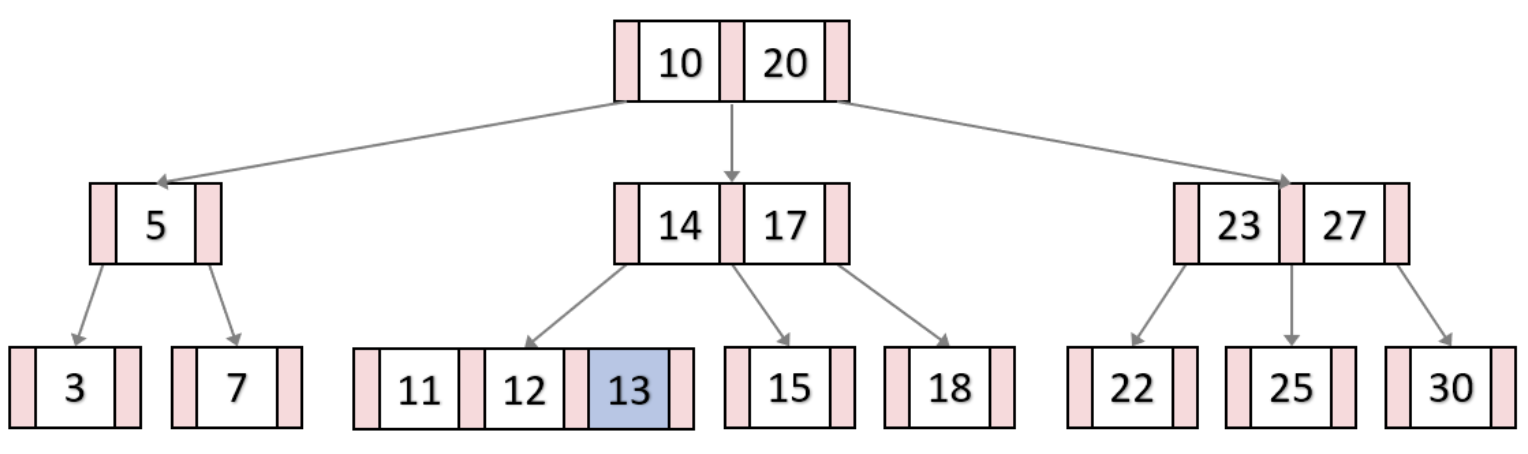
단 다차원트리인 만큼 오버플로우가 발생했을 때에는 복잡한 과정을 거친다. 오더 3인 B-Tree에서 키값 13이 삽입되는 과정에서 마지막 Leaf 노드에 오버플로우가 발생했다. 따라서 분할과정을 거친다.
[분할과정]
1) 오버플로우가 발생한 노드에서 중앙값을 부모노드로 올리고 leaf 노드는 두 개로 쪼개진다.
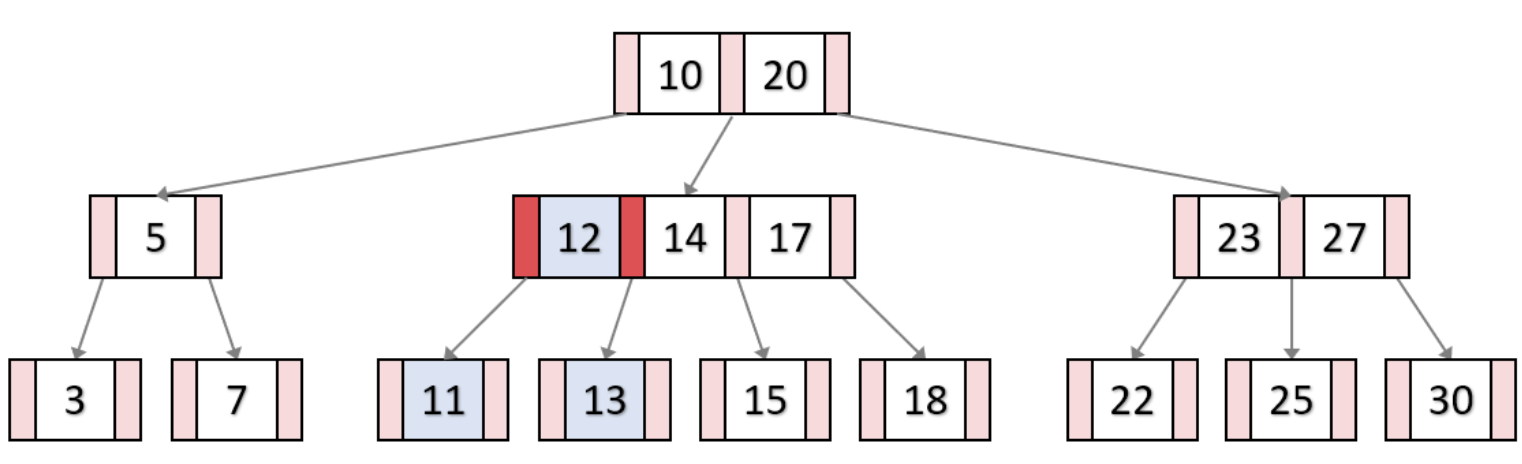
2) 부모노드에서도 오버플로우가 발생했으므로 중앙값을 기준으로 한번 더 분할한다.
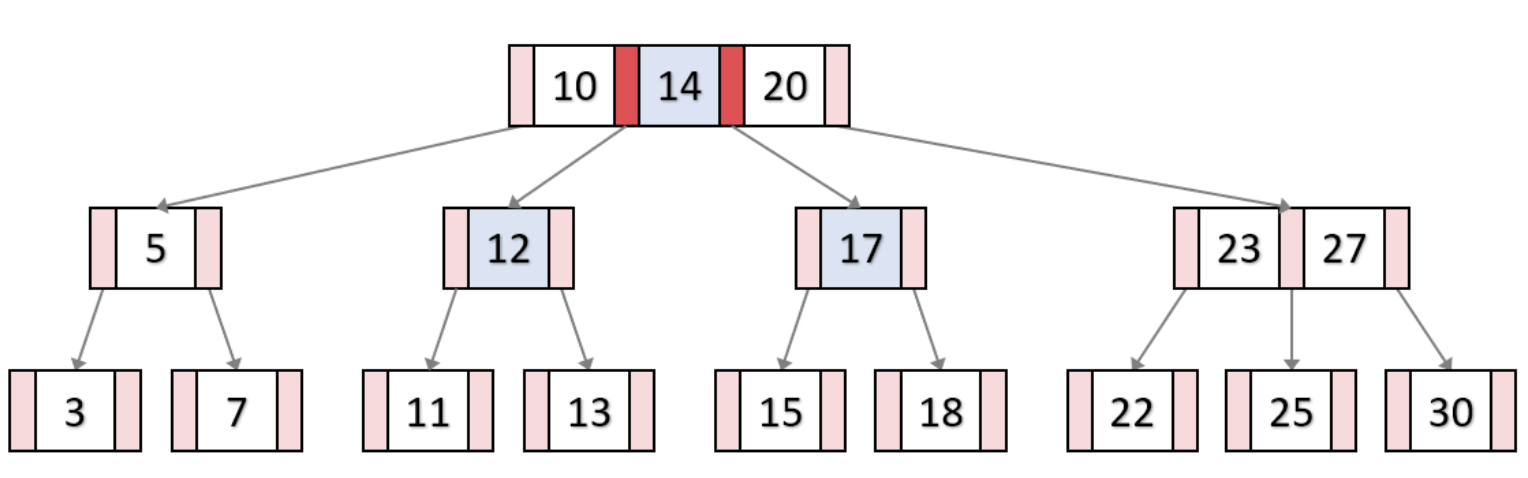
3) 오버플로우가 발생하지 않을 때까지 중앙값을 기준으로 분할하면 최종적으로 다음과 같은 구조가 된다.
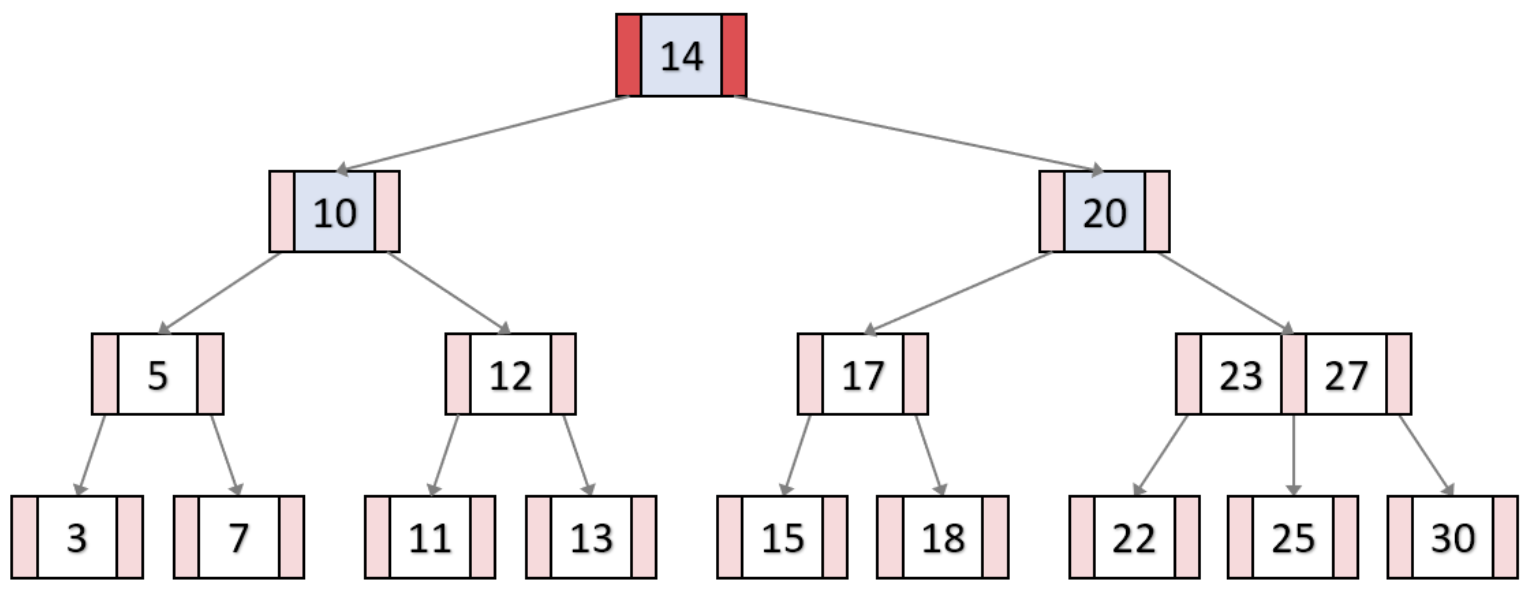
즉, 오버플로우가 발생하면 트리의 depth가 올라갈 수 있다.
[삽입에 대한 성능 분석]
leaf 노드를 시작으로 root 노드까지 오버플로우가 발생할 경우가 최악의 경우이다. 이 경우 트리의 높이까지 순회를 하기 때문에
의 성능을 보일 것이다. (노드의 자료 개수를 M/2라고 가정, 중앙값을 선택하고 트리를 재구성하는 연산은 상수 취급)
2. 삭제과정
1) 삭제할 키가 Leaf레벨에 있으면서 최소키 개수 조건(M/2)을 만족하는 경우
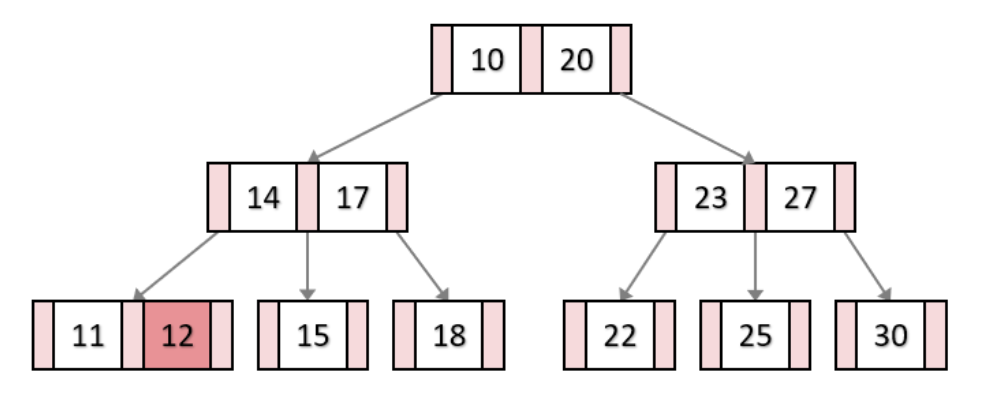
위 상태에서 키값 12를 삭제한다고 가정하면 그냥 삭제하면 된다. leaf 레벨에 있는 데이터는 삭제하는데 아무런 문제가 없다.
2) 최소키 개수 조건(M/2) 보다 작아질 경우
cf. 언더플로우: 부모노드가 가진 자료의 개수보다 자식노드가 가진 자료의 개수가 더 작아진 상태
아래 그림은 키값 15를 삭제하는 과정이다.
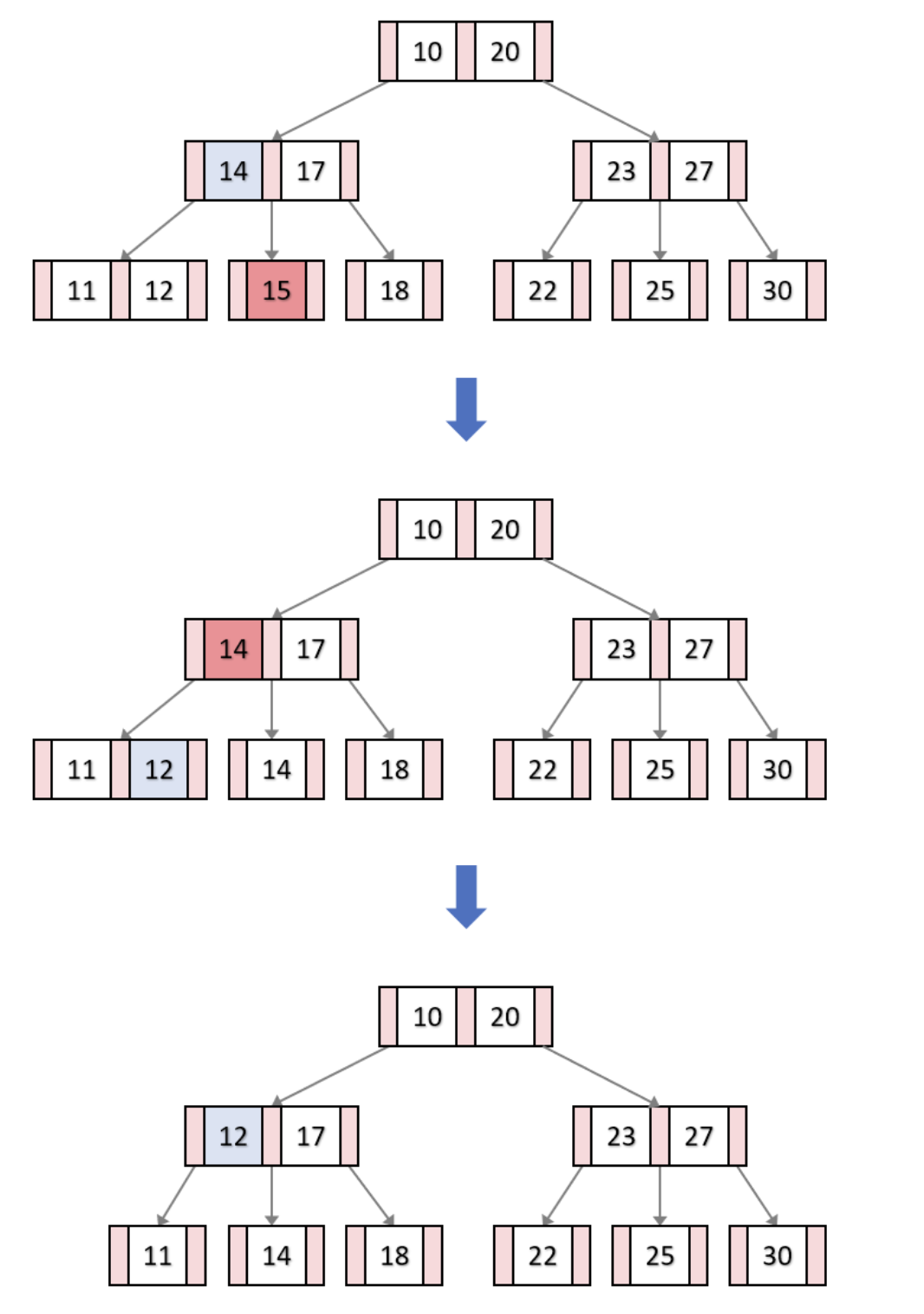
15를 삭제하게 되면 언더플로우가 발생한다. 따라서 이 경우에는 반드시 이웃노드(다른 노드는 안됨, 레벨을 유지하기 위함)의 도움을 받아 새로운 키값을 언더플로우가 발생한 노드에 채워 넣어야 한다.
정리
- 삽입과정에서 '오버플로우'가 발생하면 중앙값을 부모로 올리면서 쪼개는 과정을 반복한다.
- 삭제과정에서 '언더플로우'가 발생하면 이웃노드의 도움을 받아서 부모노드와 값을 치환하는 과정을 반복한다.
B+Tree
일반적으로 B Tree의 노드는 페이지로 구성되는데 Leaf Page(Leaf 노드)는 테이블의 키와 같이 인덱스화되어 있는 데이터(실제 키값)를 포함한다. 내부 노드(internal node)라고 하는 나머지 페이지는 검색에 사용되는 키 값의 디렉토리이다. 이때 내부 노드가 테이블의 키와 연관되는 '실제 데이터 키를 포함'할 경우를 B-Tree라고 한다. 반면에, 내부 노드가 '키 값만' 포함하며 관련 데이터는 포함하지 않는 경우에 이를 B+Tree라고 한다. 즉, 내부 노드에서 다음 단계로 가기 위한 인덱스 키만을 제공한다면 이는 B+Tree이다.
B-Tree의 경우 단건 자료 탐색을 할 때에는 트리의 root부터 시작해서 분기하면서 찾아가기에 B+Tree와의 성능은 비슷하지만, 연속된 범위탐색의 최악의 경우에는 좋지 못한 성능을 보일 수 있다. 왜냐하면, 노드의 데이터들이 서로 각각 다른 노드에 나누어져 존재하기 때문이다. 만약 탐색 대상의 범위가 하나의 페이지에 모두 존재한다면 좋겠지만, 최악의 경우에는 그렇지 않다. 따라서 순차탐색을 통해 인접한 데이터 10개를 찾는다고 가정하면 root로부터 탐색하는 횟수는 '최대' 10번 '최소' 1번이다. (캐싱되어 있지 않다고 가정, 각 노드가 담고 있는 데이터 개수에 따라 다름)
B+Tree는 일반 B-Tree의 확장판이다. B-Tree의 단점인 순차탐색에 좋지 못하다는 점을 개선한다. Leaf 레벨에 'Linked List'를 구성하여 순차탐색(range qeury)의 경우에도 좋은 성능을 보인다. 예를 들어 1부터 10까지 데이터를 찾는다고 가정하면 B-Tree는 root부터 시작하여 트리 탐색을 최대 10번 하지만(캐싱되어 있지 않다고 가정, 각 노드가 담고 있는 데이터 개수에 따라 다름), B+Tree는 1을 찾고 leaf 레벨의 LinkedList를 통해 연속된 나머지 9개의 데이터를 순차적으로 가져가기만 하면 된다.
1부터 10까지 넣었을 때 B+Tree와 B-Tree의 비교 (오더 3)
1) B+Tree
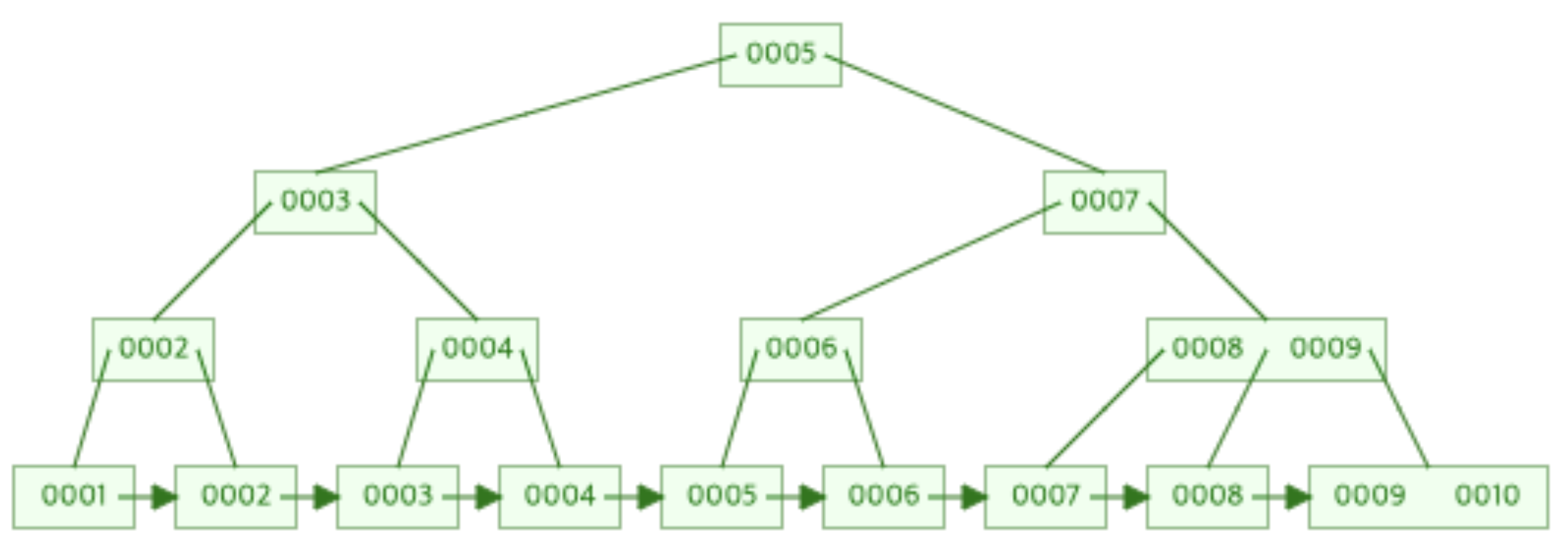
2) B-Tree
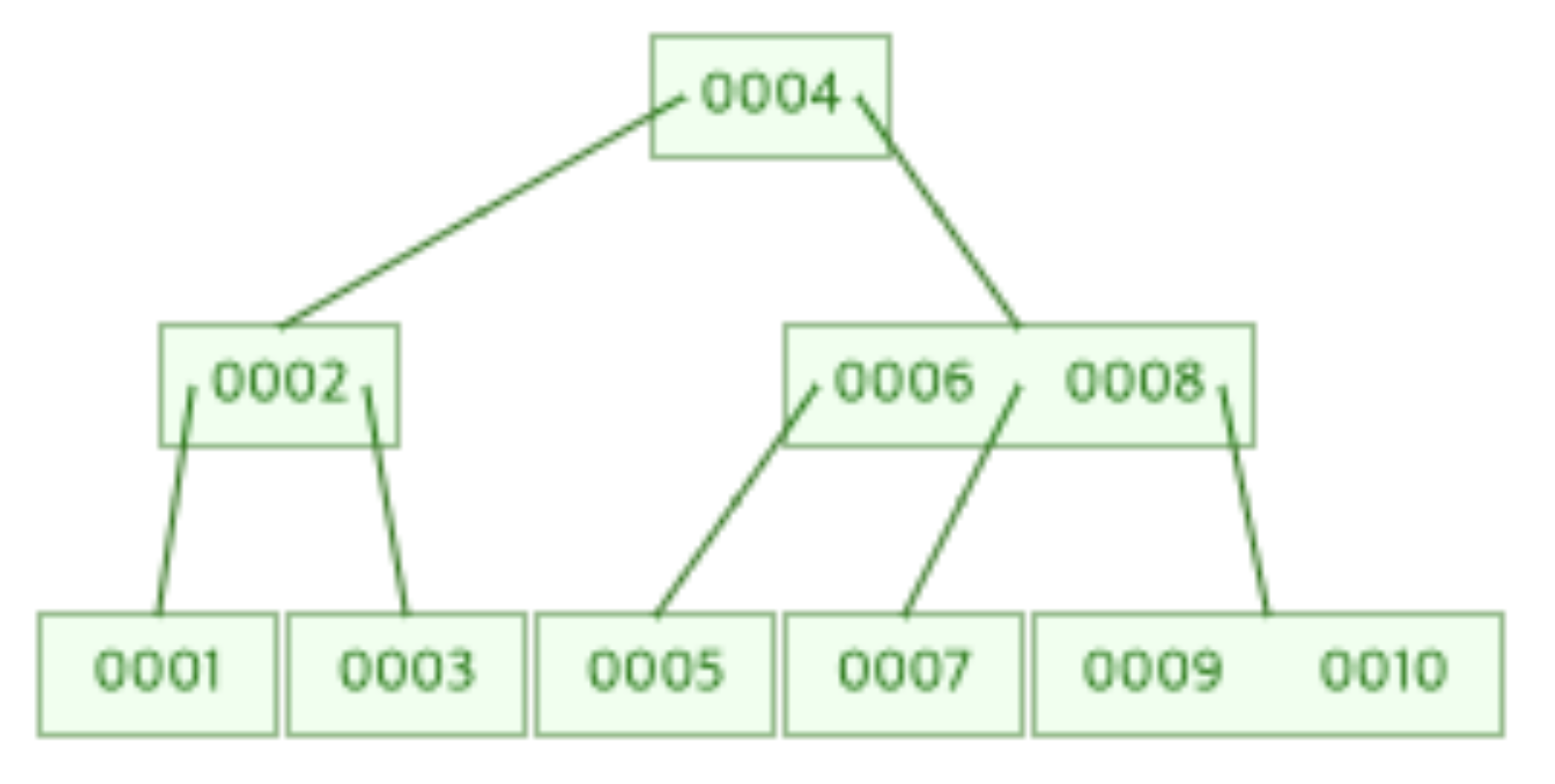
위 그림에서 1부터 10까지의 범위에 대해 순차탐색을 한다고 가정하면, B Tree의 경우 leaf까지 도달하기 위해 5번의 탐색을 진행해야 하지만, B+Tree의 경우에는 Leaf레벨에 모든 데이터들이 Linked List로 구성되어 있기 때문에 단 1번의 탐색만으로 모든 데이터를 찾아낼 수 있다.
B+Tree가 담을 수 있는 자료의 개수
B+Tree는 B-Tree와 다르게 자료가 모두 leaf노드에도 모여있기 때문에 leaf 노드가 담을 수 있는 자료의 개수를 알아본다. 위 B Tree의 성능분석 예시에서와 같이 페이지의 크기가 8KB이고 키는 8바이트, 포인터는 2바이트라고 가정했을 때 하나의 노드에 약 819개의 자료를 담을 수 있었다. 이때, B+Tree의 depth가 3이라면 약 820^2 승의 Leaf 노드를 가질 수 있을 것이다.
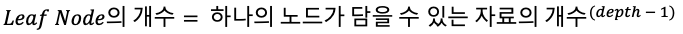
B+Tree의 depth를 3이라고 가정하면 820^2 = 672,400이다. 또한 각 리프가 400개의 레코드(자료)를 가지고 있다고 가정하면, B+Tree에 담을 수 있는 총자료의 개수는 2억 6천만 개다. 따라서 일반적으로 B+Tree의 depth가 3 이상인 경우는 드물 것이다. 따라서 B+Tree는 페이지 액세스를 최대 3번 만에 어떠한 자료에도 접근할 수 있다.(일반 B Tree도 마찬가지)
B+Tree와 하드웨어 관계
B-Tree(B+Tree)의 노드 크기는 페이지 크기와 연관되기 때문에 하드웨어와 밀접한 연관이 있다. 특히 B+Tree는 leaf 노드에 모든 데이터들이 포함되기 때문에 B Tree보다 더 많은 노드의 개수를 요구한다. 따라서 자료의 개수가 많아지면 B+Tree의 단점 중 하나는 메모리 공간을 많이 사용한다는 것이다. 이를 방지하기 위해 B+Tree의 노드들은 디스크에 상주하게 되고 이들 중 일부가 메인 메모리나 캐시에 상주하게 된다. 그중에서도 root 노드는 항상 탐색의 시작점이 되기 때문에 메인 메모리에 항상 올라와 있을 것이다. root 레벨 아래의 노드(페이지)들은 이들 중 얼마나 액세스가 되냐에 따라 메모리에 올라올지 디스크에 머무를지 결정된다. 만약 액세스 하려는 페이지가 메모리나 캐시에 캐싱되지 않았더라도, 결국 B+Tree의 depth는 4를 넘어가는 일이 거의 없기 때문에 root 노드를 제외하여 총 3번의 디스크 액세스만으로 자료를 찾을 수 있다. 즉, 대부분의 B+Tree의 depth가 높지 않다는 특성이 B+Tree의 단점을 어느정도 해결하는 결론으로 이어진다.
인덱스, 파일시스템을 B-Tree로 구성하는 이유(다른 자료구조와 비교)
- Map : 정렬되어 있지 않다.
- 레드블랙트리, AVL : 하나의 노드에 여러 자료를 담을 수 없다.(다차원 트리가 아니다)
- List : 정렬되어 있다고 가정해도 성능은 밑이 2인 로그함수에 비례할 것이다.
- Set : 탐색에는 좋을 순 있으나 범위탐색에 대해서는 매우 비효율적이다. 정렬되어 있지도 않다.
- Unbalanced BST: 최악의 경우 O(N) 이기 때문에 사용할 수 없다.
- Balanced BST: 최악의 경우 O(logN)이지만 범위탐색에 적합하지 않다. 또한 로그의 밑이 2이기 때문에 방대한 데이터를 다루기에 성능상 이점도 없다.
- B-Tree : 항상 정렬되어 있고 디스크 블록 또는 페이지 크기로 노드가 관리되기 때문에 범위탐색에도 유리하다.(최악의 경우에는 B+Tree가 더 합리적)
Reference
- https://fierycoding.tistory.com/m/78
- https://johngrib.github.io/wiki/b-tree/#fnref:bernstein-depth:1
- https://jwoop.tistory.com/15?category=1057860
- B+Tree 시뮬레이션, https://www.cs.usfca.edu/~galles/visualization/BPlusTree.html
- https://narakit.tistory.com/153
'[ Basic ] > # 알고리즘' 카테고리의 다른 글
| [백준] 2206 : DFS와 BFS차이 (0) | 2022.02.13 |
|---|---|
| 크루스칼(MST) vs 다익스트라 비교 (0) | 2022.02.03 |
| [백준] 이중 우선순위 큐 (TreeMap) (0) | 2022.01.17 |
| [DS] 레드블랙트리 (0) | 2022.01.11 |
| [백준] 12919 시간복잡도 풀이 (0) | 2022.01.05 |
- Total
- Today
- Yesterday
- Java
- helm
- go
- CICD
- GitOps
- LFCS
- golang
- kafka
- Controller
- 쿠버네티스
- Linux
- jvm
- Kubernetes
- db
- spring
- docker
- Non-Blocking
- ci/cd
- 우분투
- Stream
- ubuntu
- 카프카
- 컨트롤러
- RDB
- 코틀린
- github actions
- container
- argocd
- K8s
- rolling update
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |