2023. 8. 7. 21:09ㆍ[ 트러블슈팅-개선 ]
1. 이슈 설명
ArgoCD 설치 후 github 레포와 ssh 연결을 설정하는 과정이 실패하는 문제.
2. 원인 분석
1) 방화벽 문제
- AWS EC2의 아웃바운드 및 인바운드 규칙을 확인한 결과 아웃바운드 룰은 모두 허용이었고 인바운드 룰에 github server와 22번 포트를 열어준 상태에서도 문제는 해결되지 않음.
- 사실 아웃바운드 요청을 먼저 보내서 커넥션을 여는 상황을 의미하기 때문에 인바운드룰에 대한 설정은 현재 이슈와 상관이 없을것이라고 판단됨.
2) DNS 문제
- argocd-repo-server 로그 중 "dial tcp: lookup github.com on 10.96.0.10:53"가 있는 것으로보아, coredns 서버에 lookup을 했으나 실패한 것으로 확인됨.
- coredns 로그 확인 결과, 아래와 같이 timeout이 발생.
[ERROR] plugin/errors: 2 github.com.ap-northeast-2.compute.internal. AAAA: read udp 172.31.193.217:34760->172.31.0.2:53: i/o timeout
[ERROR] plugin/errors: 2 github.com. AAAA: read udp 172.31.193.217:50694->172.31.0.2:53: i/o timeout
로그를 살펴보면 172.31.0.2:53 는 VPC(EC2가 속한 망, 기본 설정 시 Route53)의 내부 DNS 서버 주소인데, 타임아웃이 발생한 거면 coredns가 VPC의 DNS로 요청을 보냈으나 응답이 오지 않은 상황이 발생한 것. 현재 AWS를 사용 중이기 때문에 내부 DNS(Route53) 자체에 문제가 있을 확률은 극히 드물 것.
즉, 상황을 정리해보면, Pod는 coredns(10.96.0.10:53)로 DNS lookup을 했고, coredns는 VPC의 DNS(172.31.0.2:53)로 loookup을 했으나 응답이 오지 않은 문제가 발생한 것임. 단, 요청 자체를 보내지 못했는지, 요청은 보냈으나 응답이 오지 못한 건지를 확인해 봐야 함.
cf. 그 외 시도해본 것들
[다른 Pod에서도 접근이 불가능한지 테스트]
- Pod에서 coredns(10.96.0.10)을 제대로 보고 있음.
- Pod는 coredns를 거친 다음, VPC의 DNS 서버를 사용할 수 있어야 함. 따라서 다른 Pod에서도 DNS lookup이 안되는지 테스트 진행했으나 실패.

[인터넷 자체는 잘 되는지 확인]
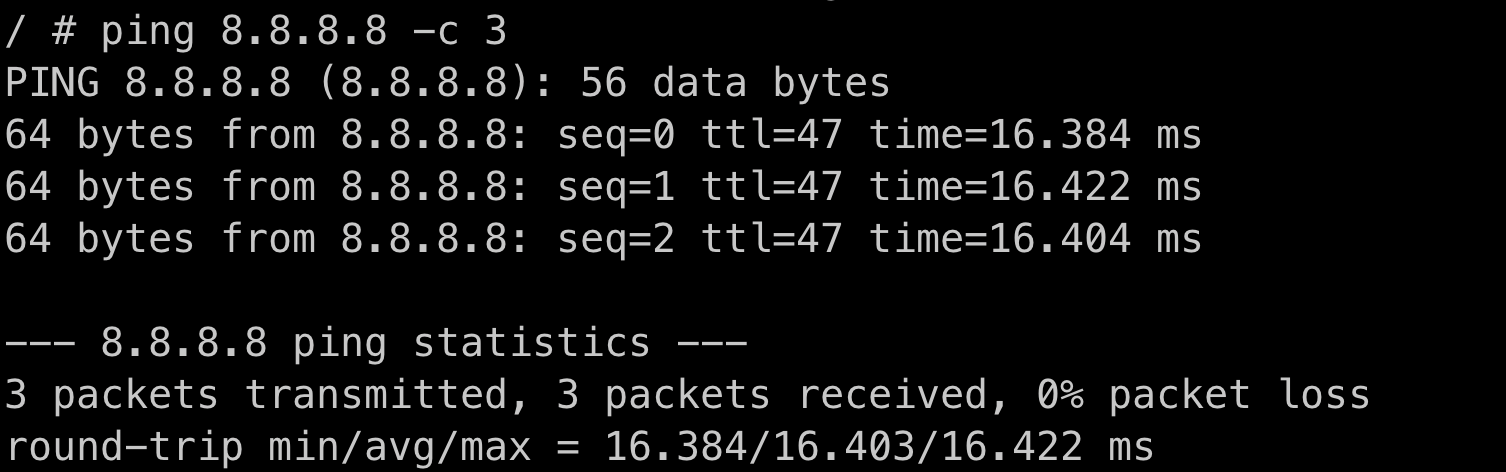
- Pod에서 8.8.8.8(Google Public DNS)로 ping이 가는것을 보면 인터넷은 정상적으로 동작중인 상태.
[호스트에서도 VPC의 DNS로 질의를 못하는지 확인]
- 호스트에서는 VPC의 DNS로 정상 질의 확인. 즉, VPC의 DNS 서버에는 문제없음.
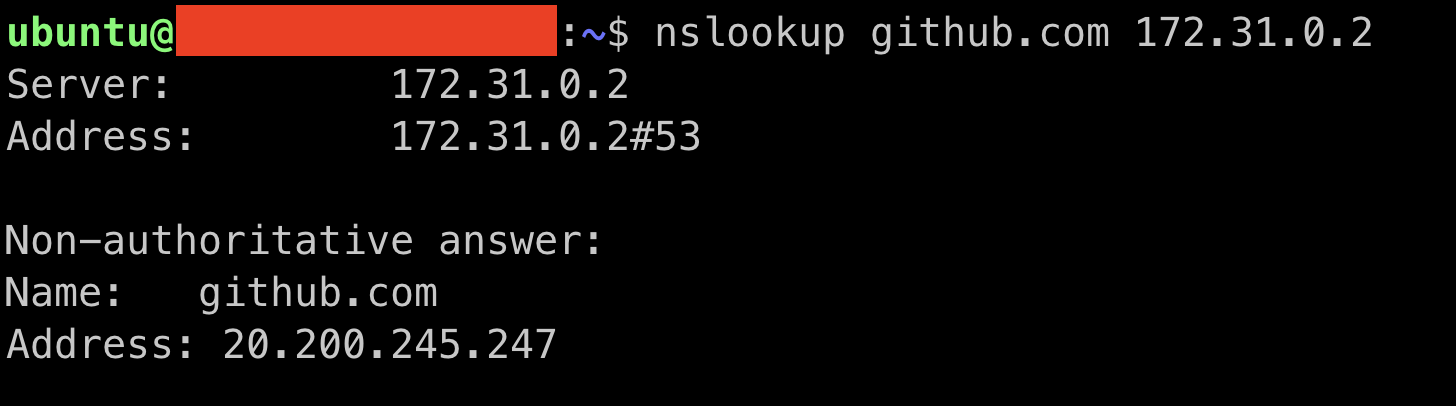
- 정리하자면 호스트 자체적으로 DNS lookup을 했을 땐 되고, Pod 내에서 DNS 룩업이 안 되는 상황인 것이므로 VPC의 DNS 서버에는 문제가 없고 coredns 단에서 룩업 요청을 보낸 것이 다른 곳으로 간 것으로 추측됨.
- 또한, Pod에서 8.8.8.8로 ping이 보내졌기 때문에 라우팅에도 문제가 없는 것임.
3) CIDR 문제
- k8s 클러스터 구축 중, Pod CIDR을 실수로 호스트의 CIDR과 같게 설정한 것이 문제가 될 수도 있을 거라 생각.
- Pod CIDR을 변경한 뒤, 문제는 해결됨.

- 결국 위 그림에서 왼쪽이 문제가 된 상황이고 오른쪽이 정상인 상황임.
- coredns에서 VPC의 DNS(Route53)으로의 DNS lookup outbound 요청은 문제가 없을 것. 왜냐하면 결국 coredns에서는 VPC의 DNS를 바라보고 있을 텐데 그쪽으로 요청 자체는 문제없이 보내졌을 것. 즉, outbound 응답 상황에서 문제가 있을 것. outbound 응답 시 먼저 호스트의 라우팅 테이블로 들어올 것이고 여기서 CNI 플러그인에 의해 라우팅 테이블이 망가져서 응답이 제대로 전달되지 못했을 것이라 판단됨.
- cidr이 pod 라우팅을 제대로 못하니깐 그걸 보고 네트워크 관리를 하는 CNI가 제대로 된 곳에 연결을 못하게 됨. 즉, 라우팅 혼선으로 인해서 라우팅 시스템이 응답을 전달해 줄 때 호스트랑 pod의 cidr이 같아버리니깐 호스트랑 pod 중에서 누구한테 응답을 줘야 하는지 모르는 상황이 된 것으로 판단됨.
- 추가적으로, 호스트에서 nslookup이 제대로 된 것을 보면 호스트를 우선시하는 것으로 판단됨.
cf. 아직 풀리지 않은 의문
- Pod에서 ping 8.8.8.8은 정상 동작하는데, DNS lookup에만 문제가 생긴 원인.
'[ 트러블슈팅-개선 ]' 카테고리의 다른 글
| [test] nGrinder 기반의 API 성능 테스트 (0) | 2022.12.16 |
|---|---|
| [k8s] NodePort 접속 오류 해결 (진행중) (0) | 2022.10.17 |
| [kubernetes] kubectl Connection Refused 이슈 해결 (0) | 2022.08.26 |
| [Jenkins] Ubuntu 20.04에서 젠킨스 포트 변경하기 (0) | 2022.06.02 |